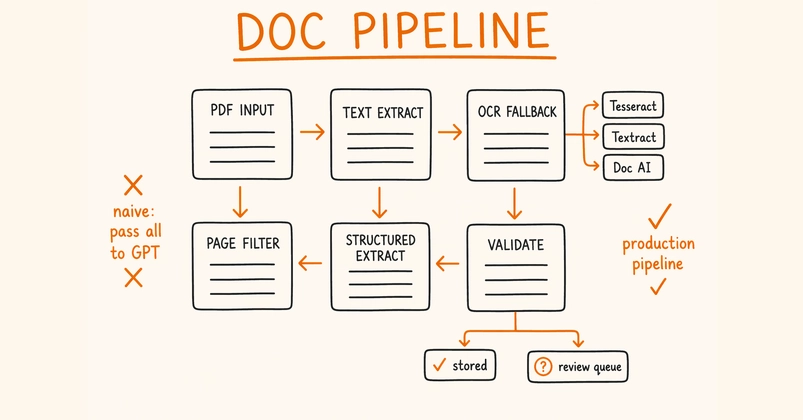
After a year running a document processing pipeline through hundreds of thousands of construction documents (tender packs, permit applications, site surveys, BIM exports, drawing sets at A0 and larger), I can tell you what actually breaks.
It is not the PDFs.
That is the thing most people get wrong about systems like this. Every PDF tutorial focuses on the parser: which library, which model, which extraction service. After a year, the PDFs themselves rank third on the list of things that break. The first is the error taxonomy. The second is coordination between documents. The actual content of the files is, mostly, a tractable engineering problem with off-the-shelf tools.
TL;DR
One pipeline run per document, not per upload. Per-document isolation pays for itself the first time a corrupt PDF lands in a 2,000-file archive.