
Self-Attention is not just “looking at important words.”
It is a matrix operation.
And that is exactly why Transformers scale.
Core Idea
Self-Attention lets each token compare itself with every other token in the same sequence.
Self-Attention is not just “looking at important words.” It is a matrix operation. And that is...
Self-Attention is not just “looking at important words.”
It is a matrix operation.
And that is exactly why Transformers scale.
Core Idea
Self-Attention lets each token compare itself with every other token in the same sequence.

The Sequence Knowledge #878: Beyond Transformer: What We Learned

How to Build Memory-Efficient Transformers with xFormers Using Packed Sequences, GQA, ALiBi, SwiGLU, and Causal Attention
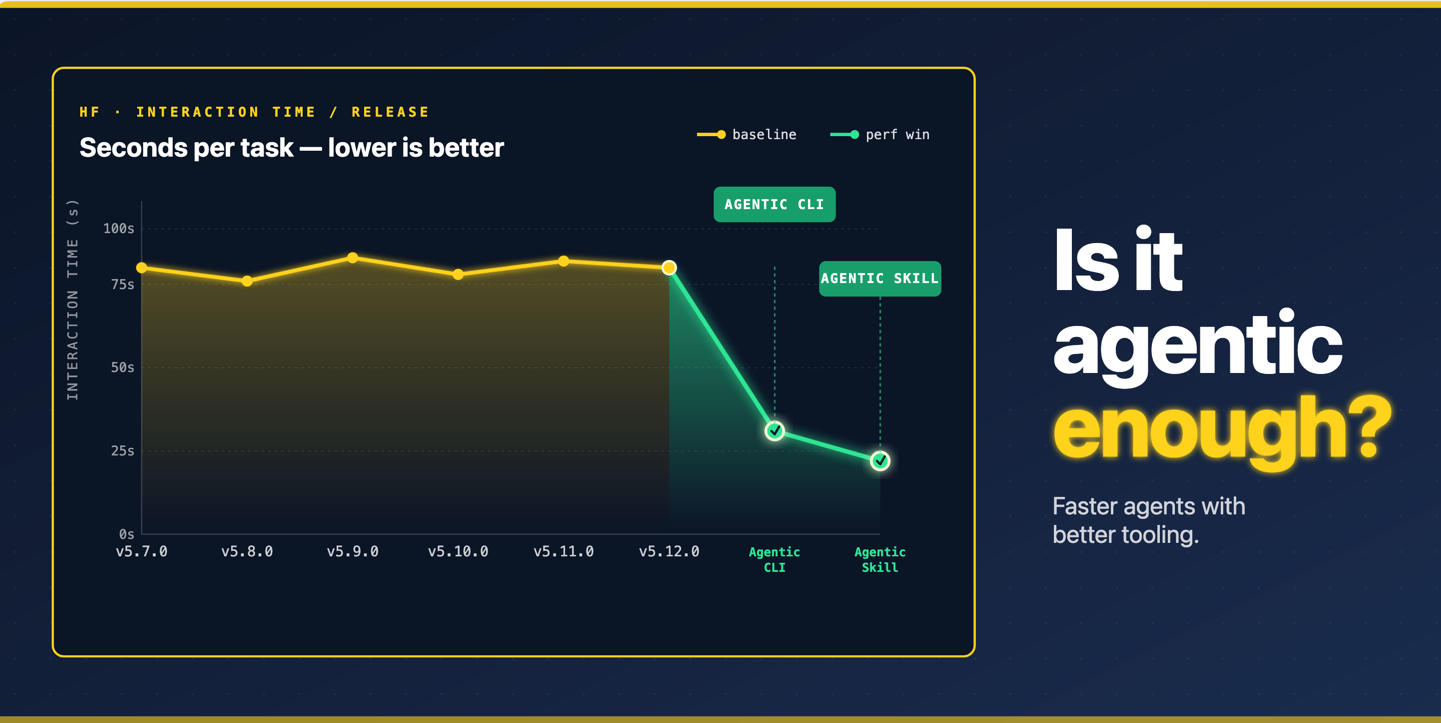
Is it agentic enough? Benchmarking open models on your own tooling
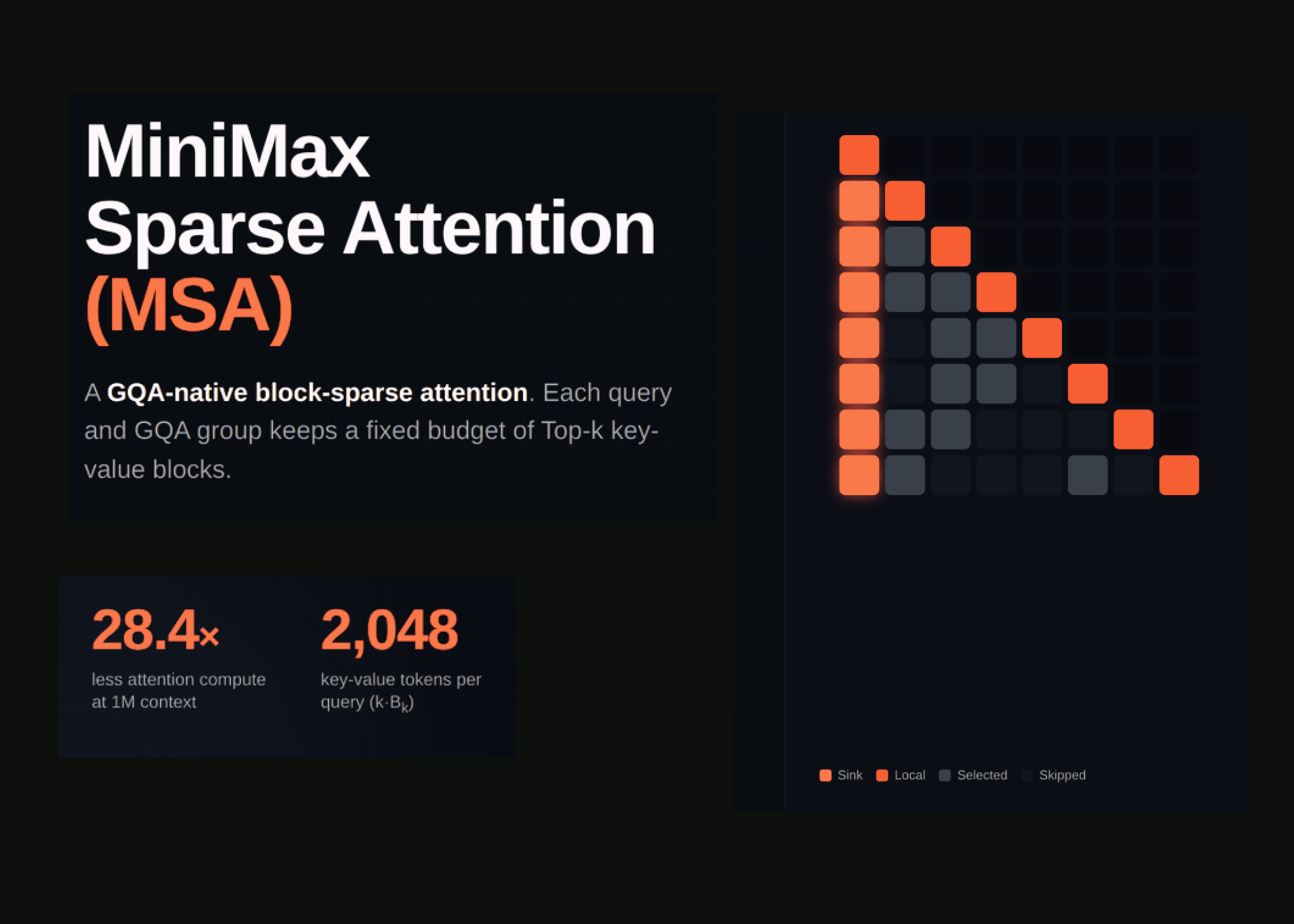
MiniMax Sparse Attention (MSA): a Two-Branch Block-Sparse Attention Trained on a 109B-Parameter MoE With a 3T-Token Budget

When people first hear about Transformers, they often encounter words like Query, Key, Value, and...

Transformers changed AI because they stopped reading sequences one token at a time. Instead of...

Learn how attention in AI works, from queries, keys, and values to KV cache, self-attention, and modern approaches
Inside the core ideas, potential and challenges of SSMs
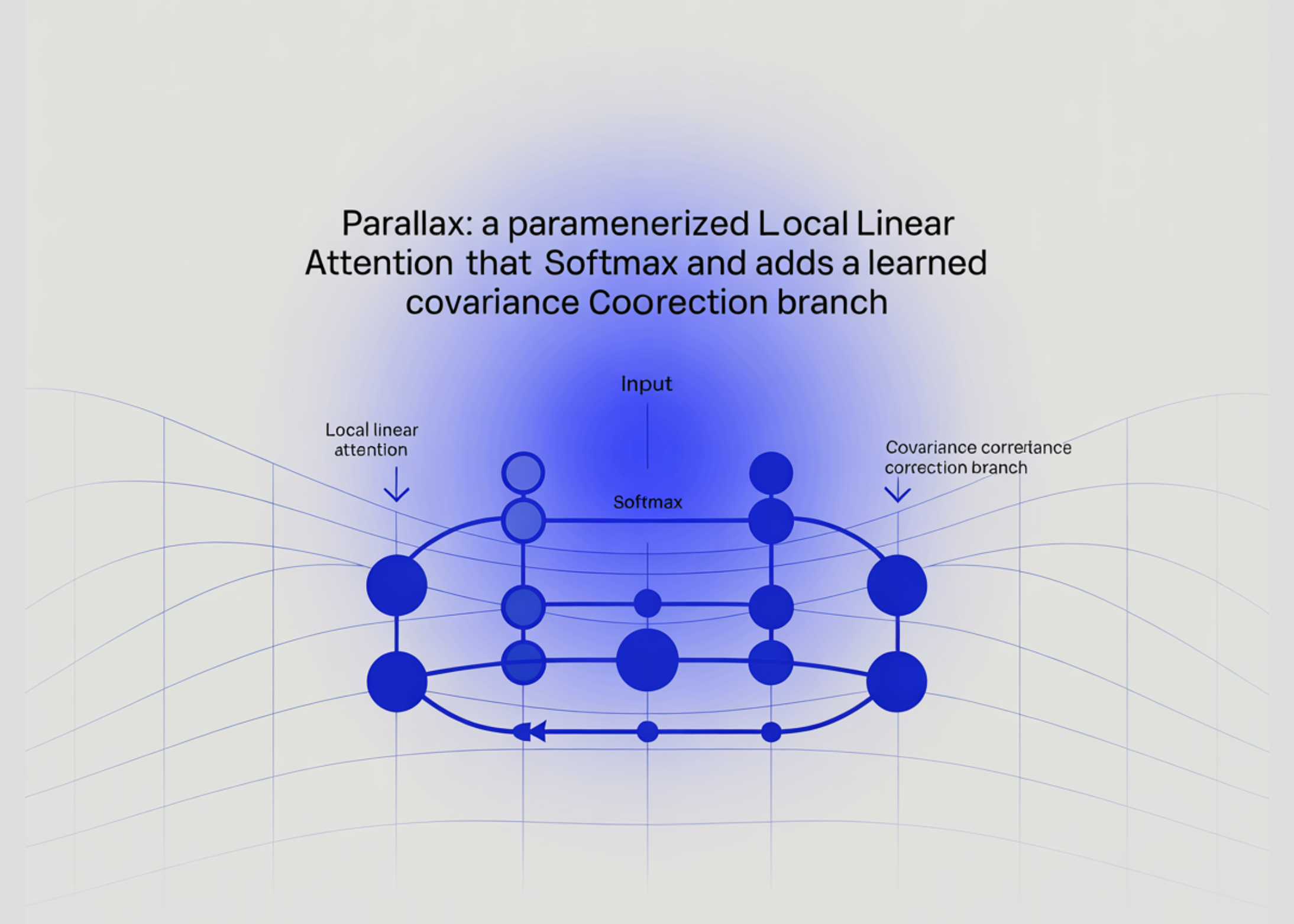
Parallax is a parameterized Local Linear Attention that keeps softmax, adds a learned covariance correction, and codesigns with…
Since its introduction, the transformer architecture has become the cornerstone of modern artificial...