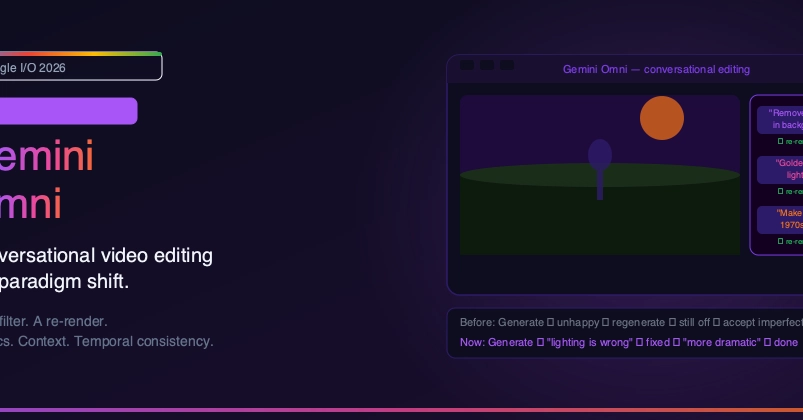
Google's demo reel for Gemini Omni looks effortless: ask for a video, then keep talking to it until the shot is right. The question for developers is whether that conversational loop holds up outside a stage demo — and what it actually changes versus the Veo workflow it replaces.
What Does Omni Add That Veo Couldn't?
Omni's core addition is state. Veo produced one-shot renders — each prompt generated a fresh clip with no memory of the last. Gemini Omni holds context across turns, so changing the camera angle on turn three preserves the characters and lighting established on turn one without restarting the scene . Announced at Google I/O on May 19, 2026, the first shipped model, Gemini Omni Flash, replaces Veo as the video-generation surface in the Gemini app .
Product director Nicole Brichtova framed it as "the next step towards combining the intelligence of Gemini with the rendering capabilities of our media models" — DeepMind's informal pitch is a "Nano Banana for video," extending conversational image editing to motion footage.
Two claims deserve a skeptical read. Google advertises "intuitive understanding of forces like gravity, kinetic energy, and fluid dynamics," but those physics behaviors currently rest on Google demos and creator footage, with no third-party benchmarks published at launch . And on raw output, independent reviewers put Omni's generation quality on par with Veo 3.1 rather than clearly above it . The differentiation is the iterative editing loop and Gemini-grounded reasoning — not a new render engine.