When Google launched Gemini three years ago, the goal was to build a multimodal large language model — a single neural network that was trained on text, image, audio, and video and could generate content in any of those formats.
Today, at its Google I/O developer conference, the company took a concrete step toward that goal with Gemini Omni, a new family of multimodal models that Google CEO Sundar Pichai says will be able to “create anything from any input.”
Omni will start with video. Users can now combine images, audio, video, and text, and rather than simply stitching those inputs together, Omni reasons across all of them to produce a consistent output. The result is high-quality videos that reflect an understanding of physics, culture, history, and science.
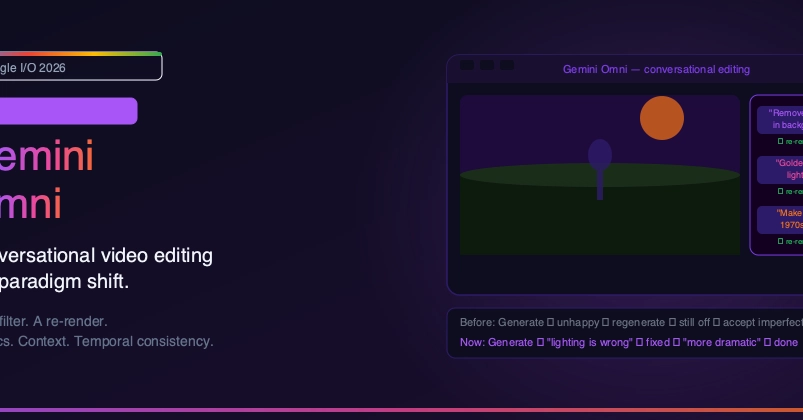
Omni also lets users edit photos with plain text commands rather than complex editing software, similar to Google’s Nano Banana.
Google already has a dedicated video model, Veo, that lets users turn text and images into videos, and even direct and customize avatars. But Google DeepMind director of product management Nicole Brichtova says that today’s release is more than a Veo update: “It’s the next step towards the progression of combining the intelligence of Gemini with the rendering capabilities of our media models.”