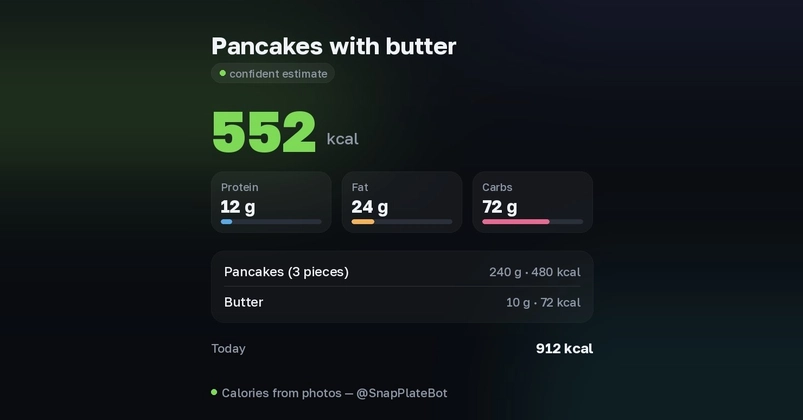
Have you ever tried to track your calories by manually searching for "half-eaten avocado toast" in a database? It’s a nightmare. While basic AI Computer Vision can identify an "apple," traditional models often fail at the granular level—distinguishing between 100g and 250g of pasta or identifying hidden toppings in a complex salad.
In this tutorial, we are building a high-precision food nutrition AI engine. By combining the Segment Anything Model (SAM) for pixel-perfect object isolation and GPT-4o Vision for multi-modal reasoning and volume estimation, we can transform a simple smartphone photo into a detailed nutritional report. If you’re looking to dive deeper into production-grade AI patterns, I highly recommend checking out the advanced engineering guides at WellAlly Blog, which served as a major inspiration for this architecture.
To achieve high accuracy, we don't just throw an image at an LLM. We use a "Segment-then-Analyze" pipeline. This ensures the LLM focuses on specific regions of interest (ROIs) rather than getting distracted by the background.
graph TD
A[User Uploads Food Image] --> B[Pre-processing with OpenCV]