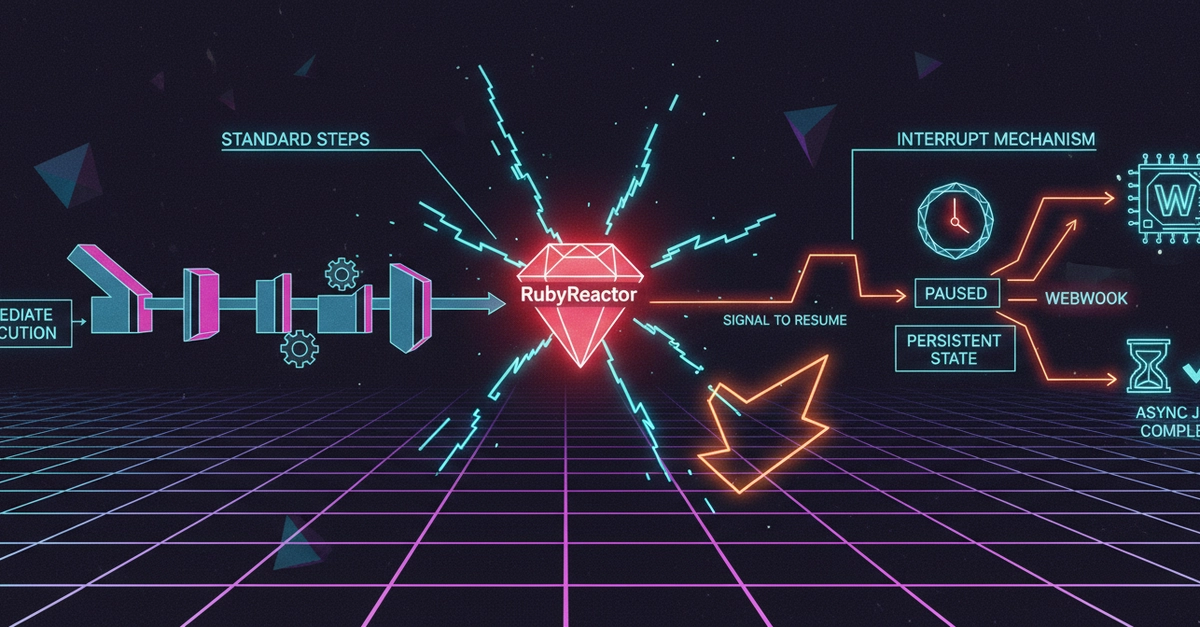
Every non-trivial business operation touches more than one system.
An e-commerce order reserves inventory, charges a payment method, and schedules a shipment — three services, three databases. A bank transfer debits one account and credits another across two ledgers that may not even be in the same data center. A cloud VM provisioning workflow reserves a network port, allocates storage, starts the hypervisor, registers billing, and sends a notification — five services, five independent state stores.
The question is: what happens when step four fails after steps one through three have already succeeded?
In a monolith backed by a single database, the answer is simple: roll back the transaction. The database engine guarantees atomicity; either everything commits or nothing does. But when your workflow spans multiple services, each owning its own storage, there is no transaction boundary that wraps them all. There is no rollback button. Step one through three have already made durable changes to systems that do not know about each other, and step four's failure has left the system in an inconsistent state.
This is not a pathological edge case. It is the default condition in any distributed architecture. And it gets worse: the failure might not be a hard error. The network might time out. The billing service might return a 503. You do not know whether step four applied its effect or not — you only know you did not receive a success response. Now what?