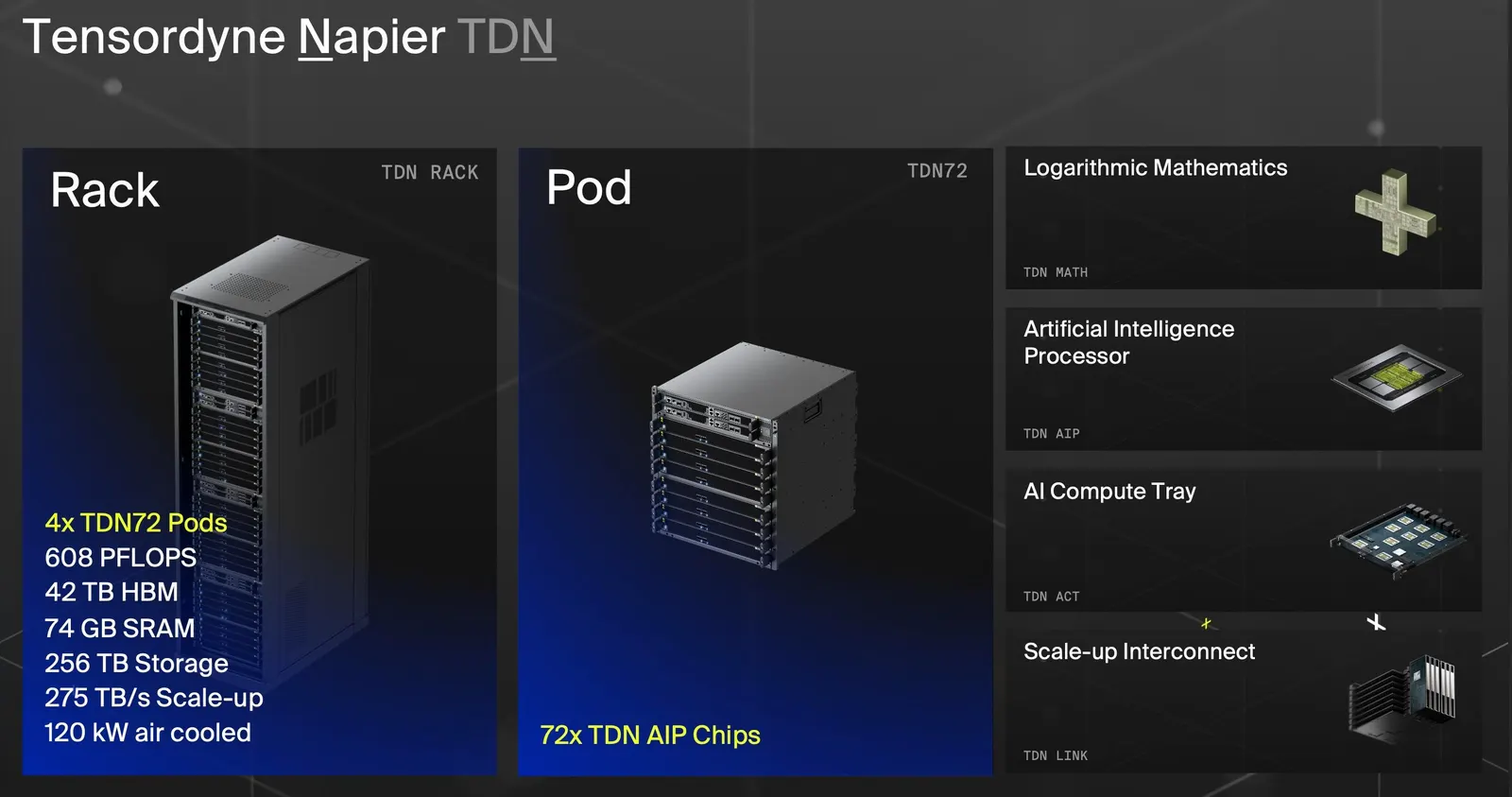
Tensordyne, a startup with offices in Sunnyvale and Munich, announced its Napier (TDN) AI inference processor on June 15, claiming its TDN72 rack-scale system delivers 13 times higher throughput in tokens per second and 17 times more tokens per watt than Nvidia’s GB300 NVL72 rack. The comparison benchmark: DeepSeek-R1 inference workloads.
The numbers behind the claim
Tensordyne says a single rack running its hardware can churn out roughly 363,000 tokens per second. The company pegs Nvidia’s equivalent rack at approximately 27,400 tokens per second on the same workload.
The secret sauce is something called a logarithmic number system, or LNS, executed directly in hardware. Instead of doing math the way conventional chips do (multiplying big floating-point numbers together), LNS converts multiplication into addition, which is dramatically cheaper in terms of transistors and energy. It’s a technique that’s been studied in academia for decades but has historically been too impractical for production silicon.
Tensordyne built its Napier chip on TSMC’s 3nm process node, integrating both SRAM and HBM memory on-package. The full rack configuration stacks four pods of 72 chips each, totaling 288 chips, with a target power envelope of roughly 120 kW for the entire rack. That’s air-cooled, not liquid-cooled.