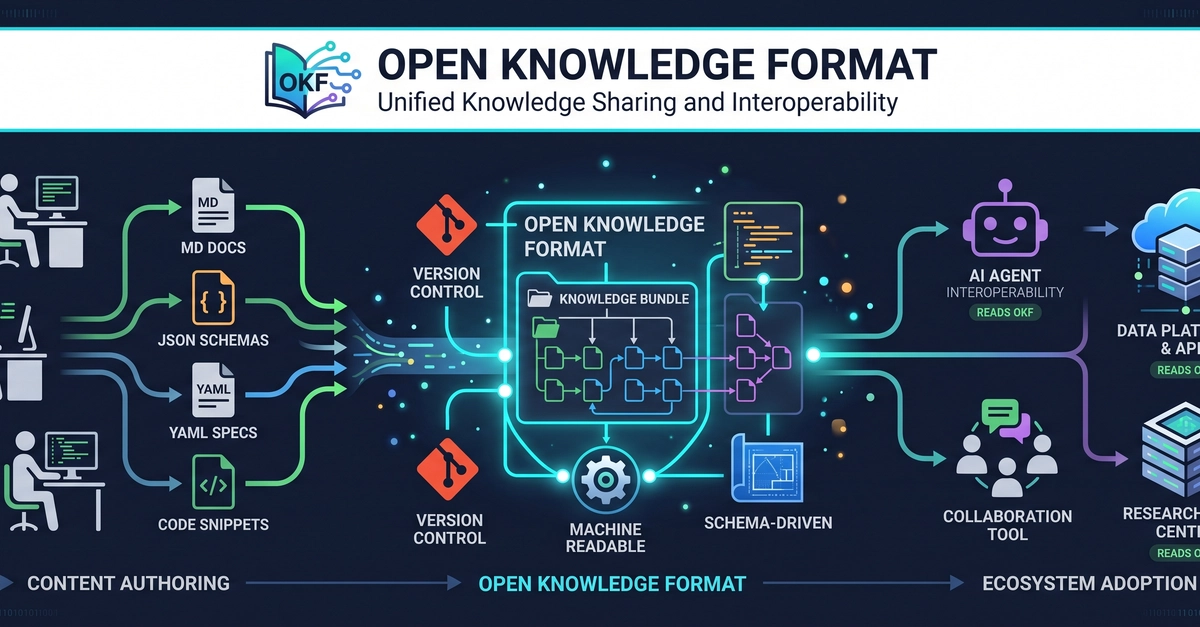
Most teams don’t suffer from a lack of data. They suffer from a lack of shared context. Definitions, caveats, ownership, and “how to use this safely” guidance end up scattered across wikis, tickets, dashboards, and people’s heads. Google’s Open Knowledge Format (OKF) tackles that sprawl by packaging curated context as a portable, versionable bundle of “just files” that both humans and AI agents can consume reliably (Google Cloud Blog, Jun 12 2026, OKF SPEC.md).
This article covers the problem OKF targets, what the format is (and isn’t), and the building blocks that make it work. It then explains why OKF fits developer workflows and content operations, plus adoption patterns, tradeoffs, and practical next steps.
The real problem OKF is trying to solve: “context sprawl”
OKF exists because the most important knowledge in an organization often isn’t the data itself. It’s the context around the data, and that context is scattered. Google describes this as “metadata, context, and curated knowledge” spread across too many surfaces to share or reuse cleanly (Google Cloud Blog, Jun 12 2026).
This fragmentation hurts humans. It hurts AI agents and cross-team work even more. People compensate with experience. They know which wiki is “more correct,” who to ask, and which dashboard is legacy. Agents don’t have that intuition. When context is missing or split across systems, an agent has to infer and guess. That leads to confident wrong answers and brittle automations.