Over the last few weeks, I’ve open-sourced a suite of high-performance, zero-dependency C# engines. This includes a native DataFrame library (Glacier.Polaris), a blistering fast text searcher (Glacier.Grep), and a semantic Markdown parser for RAG contexts (Glacier.DocTree). You can find the source code for all of these on my GitHub.
A recurring question I’m getting from other devs looking at these repositories is simple: How exactly are you bypassing the Garbage Collector to get these speeds?
I’ve never hidden my distaste for heavy, magic-filled frameworks. Whether it's an unwieldy data access library or a bloated client-side framework, they all share a common flaw: they wrap your code in layers of hidden allocations that murder your CPU caches and force the .NET Garbage Collector (GC) into overdrive.
When you want to build systems that process millions of rows a second or rival native C/C++ in raw compute speed, you have to take control of your memory. To give you a fighting chance at writing your own high-performance engines, let's break down how memory allocation actually works in C#, using the architecture of the Glacier repositories as our guide.
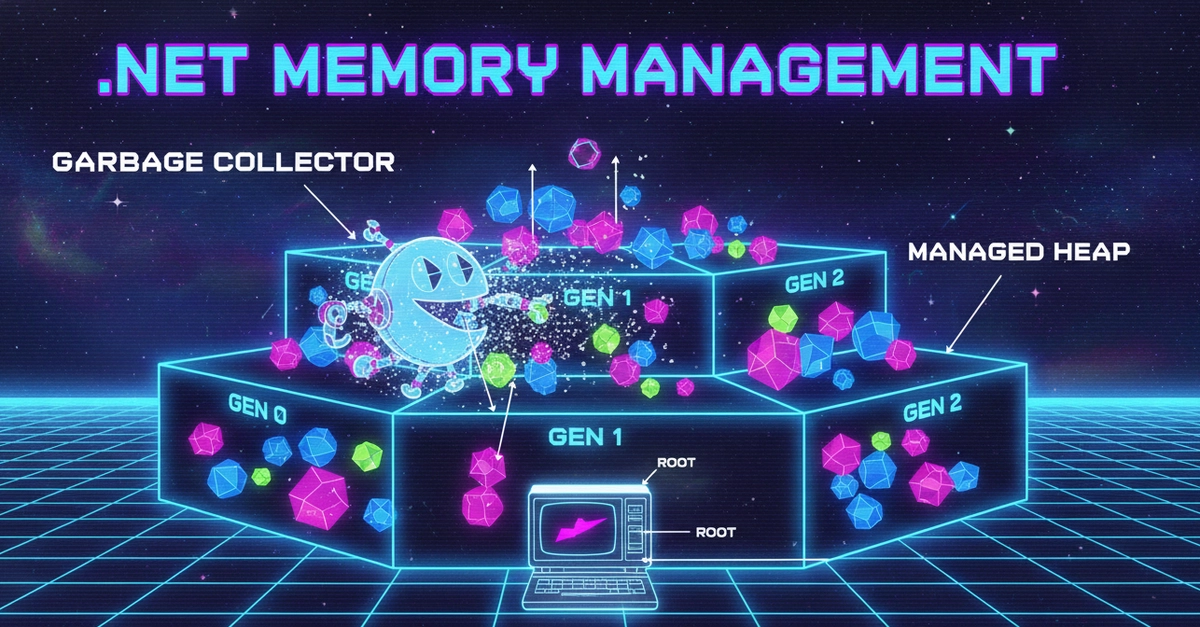
Level 1: The Heap, the Stack, and Cache Locality