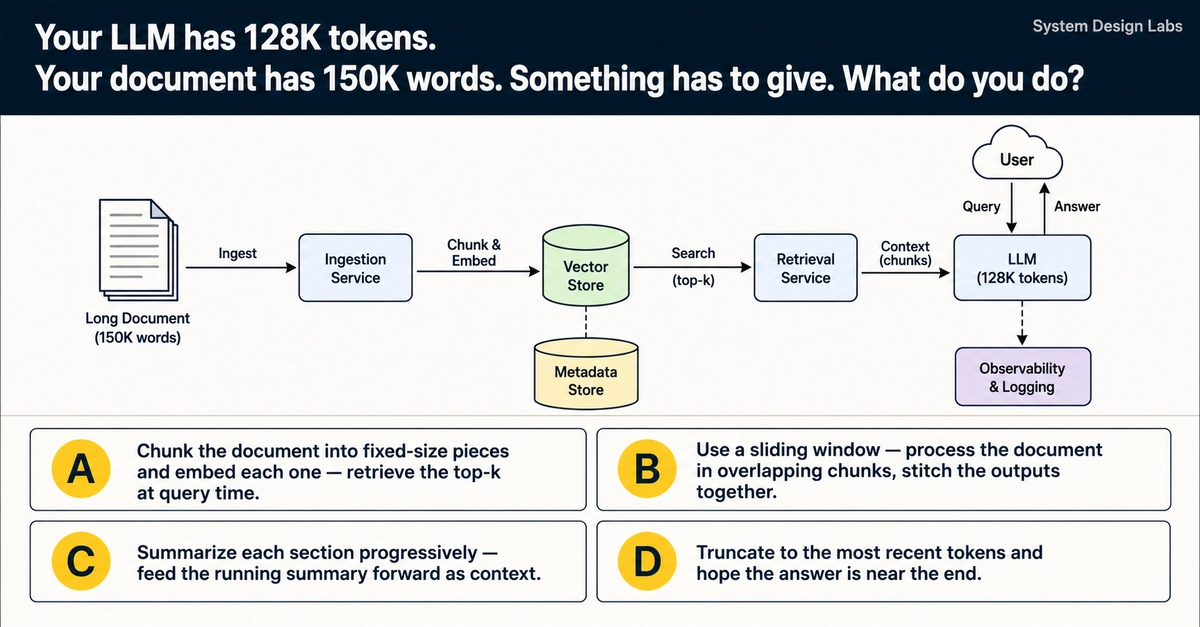
Your LLM has 128K tokens.
Your document has 150K words.
Something has to give. What do you do?
A) Chunk the document into fixed-size pieces and embed each one — retrieve the top-k at query time.
B) Use a sliding window — process the document in overlapping chunks, stitch the outputs together.