A few months ago, I was building a system to answer questions from 100-page technical PDFs. You know the drill: a user uploads a manual, asks “What’s the torque spec for bolt A?” and wants an accurate answer fast. What I thought would be a quick LangChain script turned into a weeks-long battle with token limits, hallucination, and cost explosions. Here’s what I learned.
The Problem
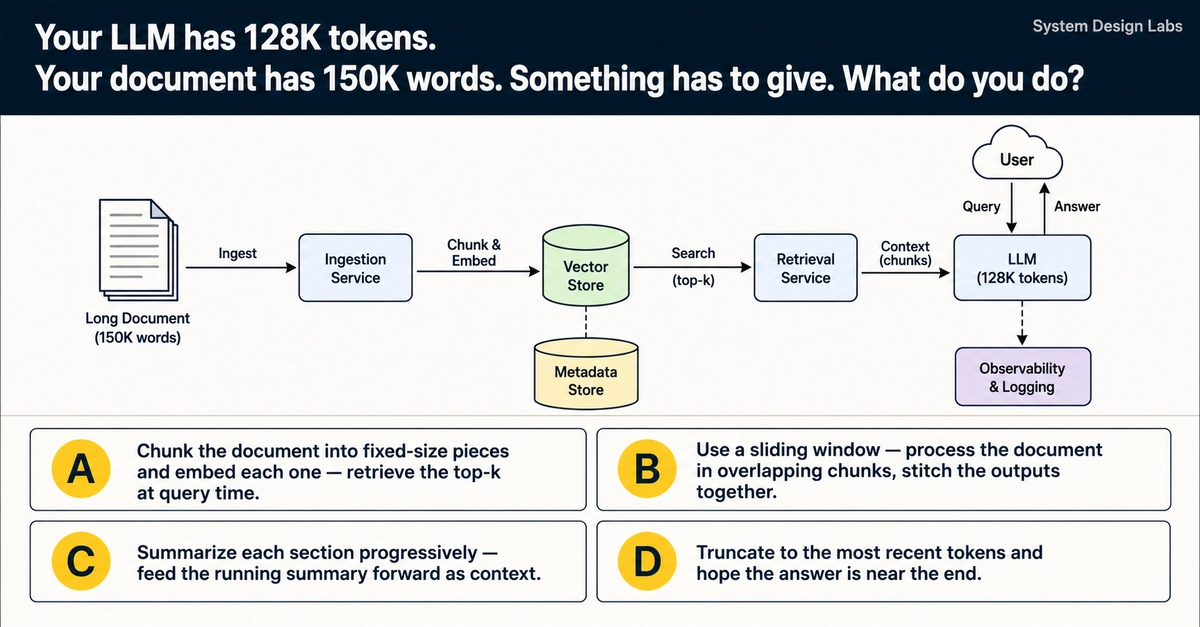
I had a client who needed to make sense of legacy engineering documents. Each PDF was dense, with tables, diagrams, and footnotes. My first prototype used GPT-4 with the full text crammed into a prompt. That worked for 10-page docs, but at 100 pages I hit the 128K token cap even before adding the question. And if I squeezed it in, the model would “forget” details from the middle (the lost-in-the-middle effect). Cost per query was laughable — $0.50+ per call.
I needed a solution that could handle arbitrarily long documents, return accurate answers, and not bankrupt us.
What I Tried (and Failed At)