Back to Articles
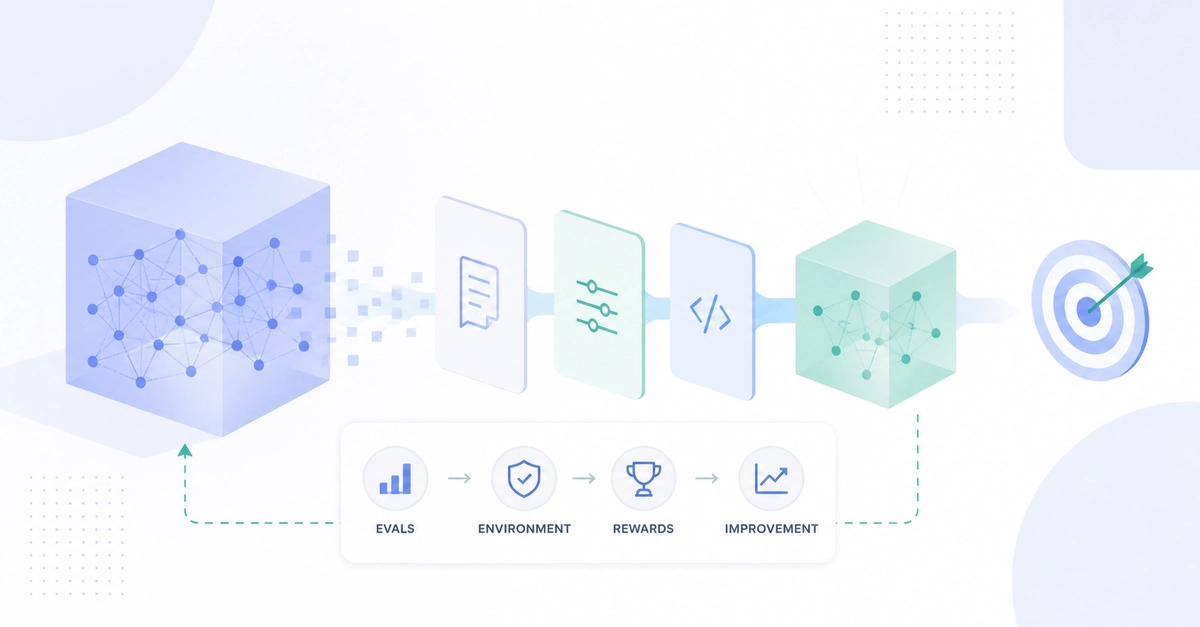
While you're building an LLM, you evaluate it over and over across many interventions. Every adjustment to its data, architecture, or hyperparameters — and every step up in scale — sends you back through the same loop: adding or reconfiguring benchmarks, re-running them on each new model checkpoint, noting the results, and checking whether something that helped in a small experiment still holds up on the full training run.
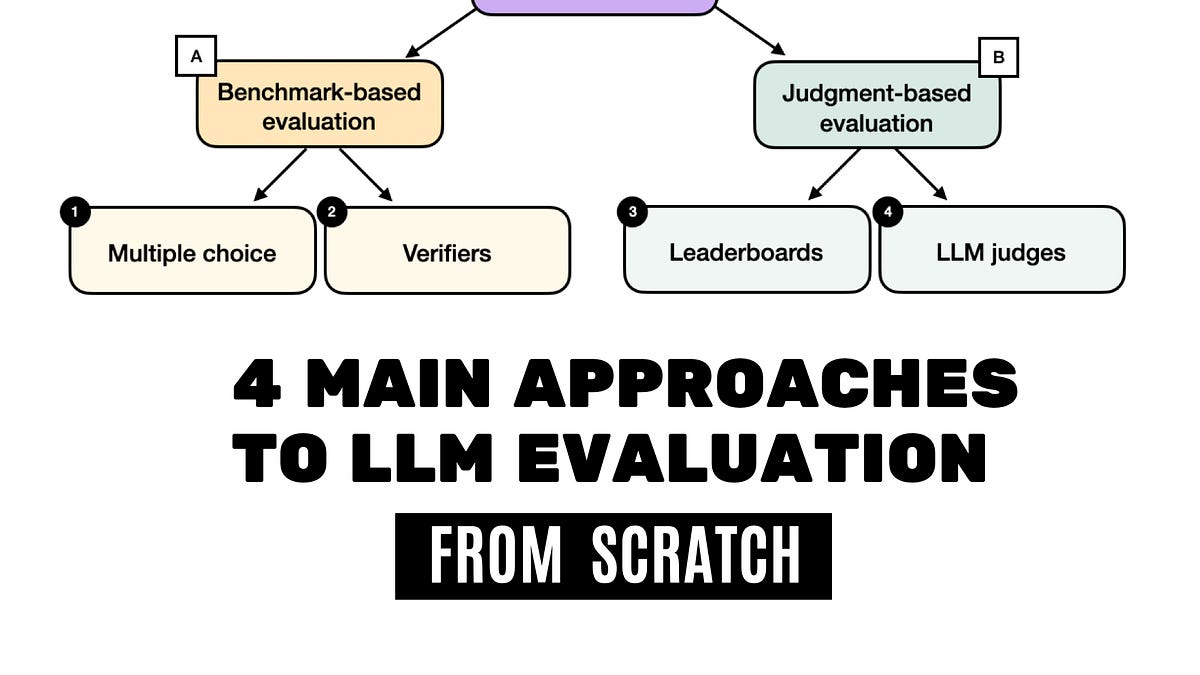
Most evaluation tools aren't designed for this—they’re either built to run established benchmarks across finished models or run a model through multi-step, tool-using problems in a sandbox. They don’t keep up with a model that's constantly changing, nor do they reflect how a model might behave under specific real-world conditions.
Our last project to address this evaluation challenge was OLMES, the Open Language Model Evaluation Standard. Introduced in 2024, it was meant to make LLM benchmark scores easier to compare across releases. The same models were being scored on the same benchmarks in different ways — aspects like prompt formatting and task formulation often varied from paper to paper — so claims about which models performed best often weren't reproducible. OLMES pinned benchmarking choices down in an open, documented standard, and it became the basis for evaluating our open models from Olmo to Tulu.