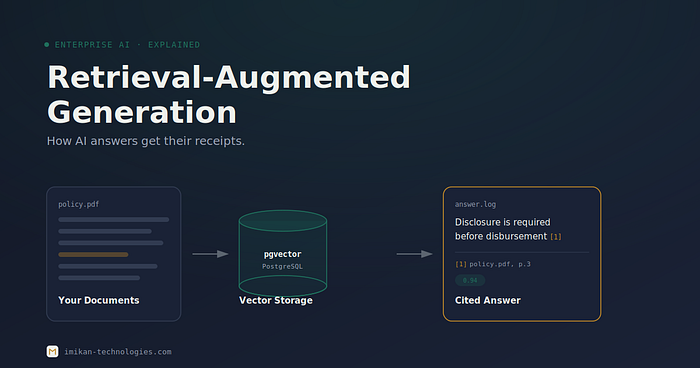
Large language models are confidently wrong about anything they were not trained on: your internal docs, last week's release notes, that niche product you built. RAG (Retrieval-Augmented Generation) is the fix. Instead of fine tuning, you fetch the relevant text at question time and hand it to the model as context.
In this tutorial we will build a small but real RAG chatbot that answers questions about a private knowledge base. No heavy frameworks, so you can see every moving part. By the end you will have roughly 40 lines of Python that you can point at your own data.
How RAG works
The whole pipeline is five steps:
your docs --> chunk --> embed --> store