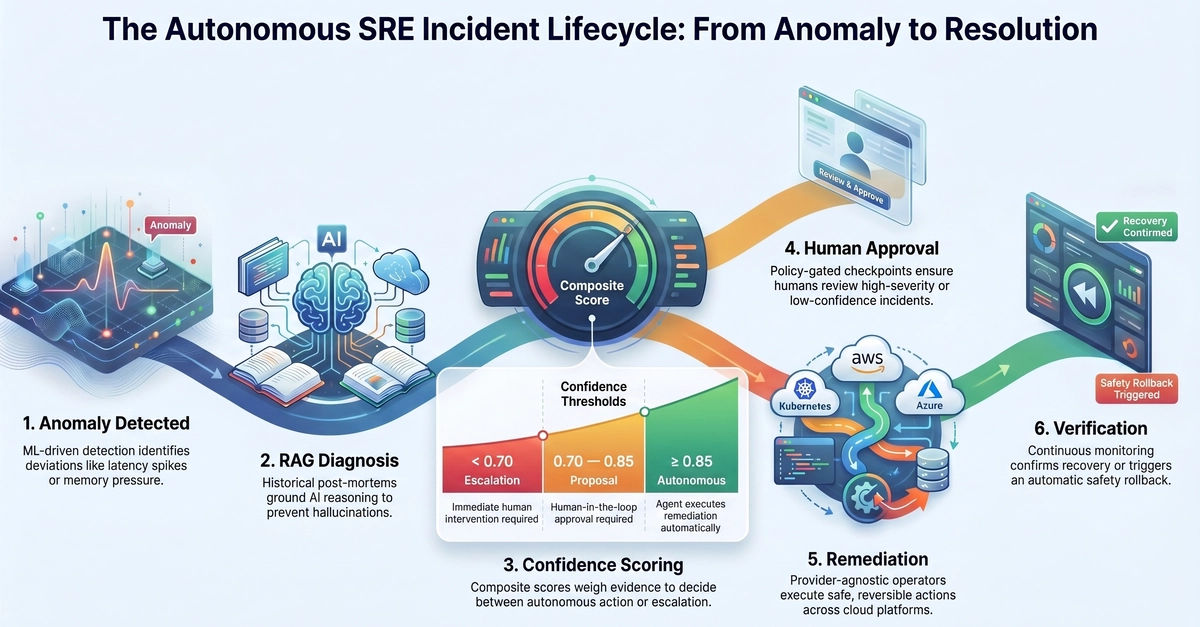
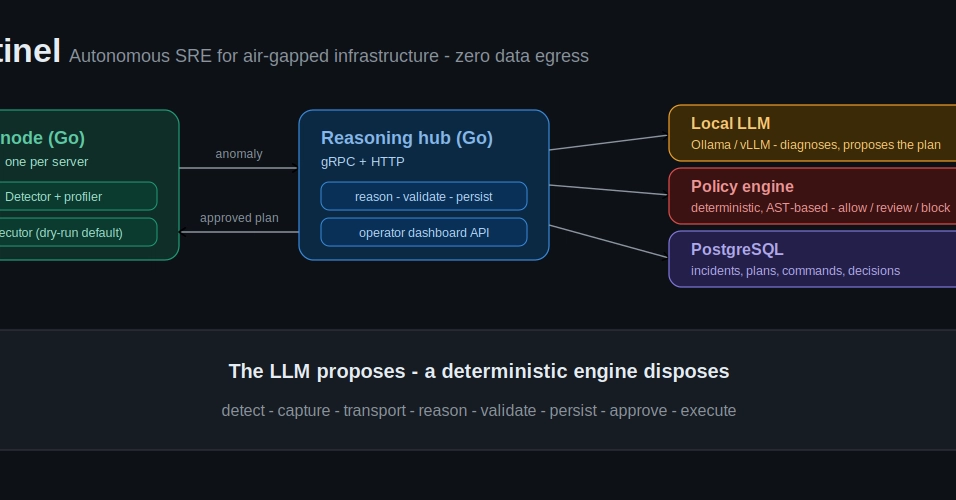
Part I of two. Part II will be published next week, and will show the same loop end-to-end against HolmesGPT on a real cluster.
You're rolling out an AI-SRE (your own homegrown in-house AI loop, or one of the new products: Resolve AI, incident.io's Investigator, Datadog Bits). When an alert fires, it proposes a fix: a timeout here, a retry there, a config bump. The suggestion looks plausible. Do you merge it?
Today, you read the diff, eyeball it against your mental model of the service, and decide, or you deploy to staging and wait. The bugs an AI-SRE gets paged on (an unhandled exception under a rare request shape, a downstream that times out for some requests, a webhook that races with itself, a slow query that only surfaces at scale) live in the gap between local and production. Unit tests and mocks don't reach there. Staging does, but staging is slow (a deploy on every iteration) and shared (you're competing with everyone else trying to reproduce their own bugs).
This is where mirrord can help. mirrord runs a separate copy of your service as if it were a pod in your cluster, wired into the same real downstreams and upstreams without a deploy. This guide shows how to wire that into your AI-SRE so every suggested fix is verified against the real cluster before it reaches a human, automatically, in no time, with no SDK or code to import.