Modern Site Reliability Engineering (SRE) teams manage hundreds of microservices with complex interdependencies. When an incident occurs, engineers must manually query multiple observability backends, correlate signals across layers, consult historical post-mortems, and execute runbooks. This manual process leads to high Mean Time to Recovery (MTTR), alert fatigue, and operational toil.
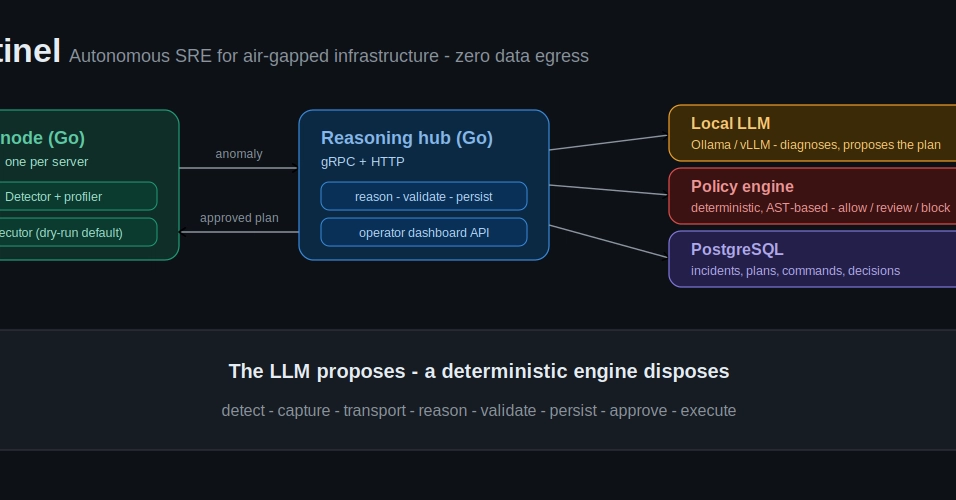
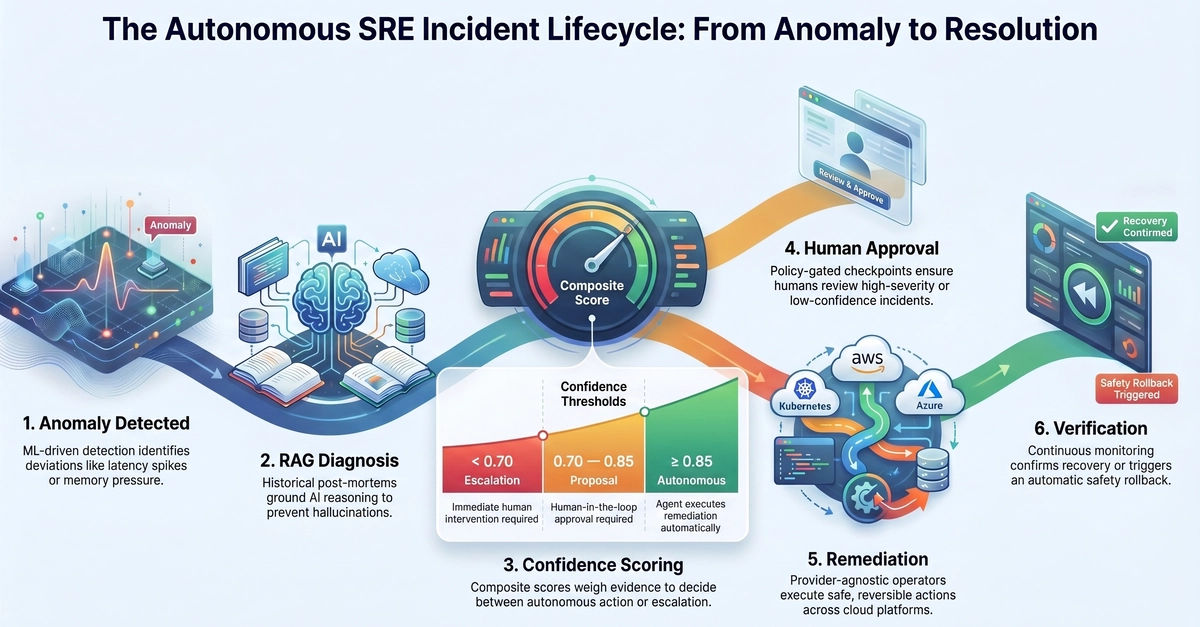
To solve this, I built the Autonomous SRE Agent—an AI-powered reliability system that executes the full incident loop (detect → investigate → diagnose → remediate → learn).
Unlike simplistic AI wrappers that execute LLM outputs blindly, this agent is built on a rigorous Hexagonal Architecture with hard-coded safety guardrails, ensuring that autonomy is earned through a strict phased rollout, rather than granted by default.
Here is a deep dive into the purpose, architecture, and implementation of the Autonomous SRE Agent.
The Autonomous SRE Agent is designed to completely automate the triage and remediation of well-understood infrastructure incidents, reducing MTTR to sub-30-second diagnostic latency.