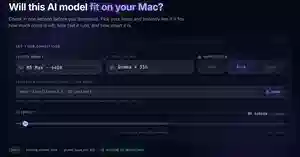
You already know what --n-gpu-layers does. It moves transformer layers onto your GPU. This post is the next step: how to actually pick the number.
If you want the basics first, read the original: llama.cpp n-gpu-layers explained. This is the tuning guide that follows it.
The one rule that matters
A model has a fixed number of layers. A 7B model might have 32. A 70B might have 80. The --n-gpu-layers flag (often shortened to ngl) says how many of those go on the GPU. The rest stay on the CPU and run in system RAM.
Full GPU means fast. Full CPU means slow. Partial means somewhere in between, and it scales close to linearly. Offload half the layers and you get roughly half the speedup.