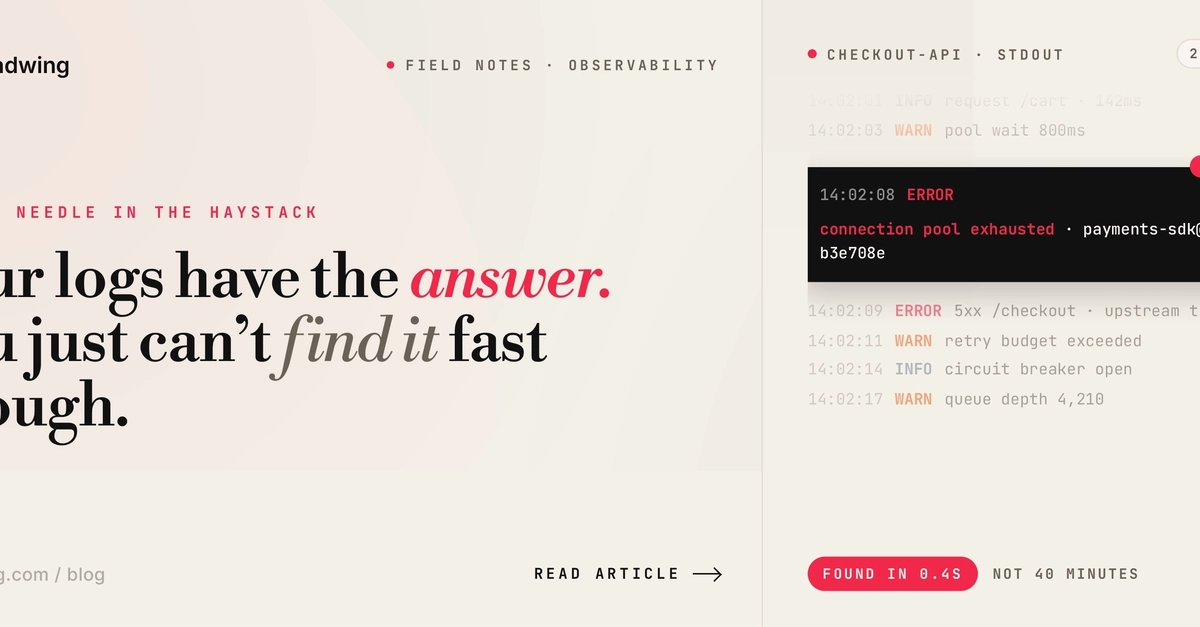
Three weeks ago, one of the teams we work with had a checkout outage. The root cause a malformed database query introduced in a deploy 40 minutes earlier was sitting in their CloudWatch logs the entire time. Timestamped. Stack-traced. Perfectly clear.
They found it 22 minutes after the alert fired.
Not because they weren't looking. Because they were looking in Elasticsearch first. Their checkout service logs to CloudWatch, but the API gateway that routes to checkout logs to Elasticsearch. The engineer on call didn't remember which was which. So they spent 8 minutes searching Elasticsearch, found nothing relevant, switched to CloudWatch, spent another 6 minutes getting the query syntax right, then another 8 minutes narrowing the time window to find the specific error.
Twenty-two minutes. The log line had been sitting there since minute one.
This isn't a story about a bad engineer or bad tooling. It's a story about what happens when incident data is scattered across platforms that don't talk to each other.





