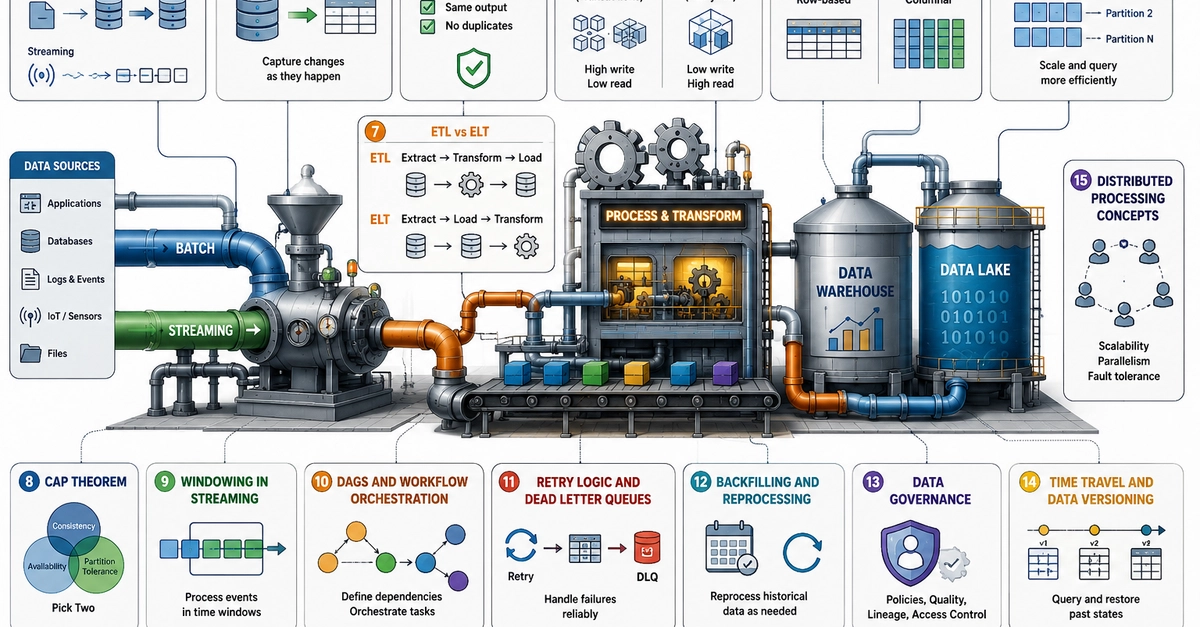
When you are starting out in Data Engineering, it is easy to focus entirely on writing pristine Python code, designing SQL schemas, or learning complex tools like Apache Spark. But sooner rather than later, you’ll realize that data engineering isn't done in a vacuum. Most of our day-to-day work involves wrestling with data infrastructure.
We are constantly moving files around, orchestrating automated tasks and debugging code running inside containers.
At the heart of almost all modern data infrastructure is Linux.
For many beginners, stepping away from a visual desktop and into the Linux terminal can feel like stepping into a sci-fi movie. A blinking cursor on a blank screen isn't exactly welcoming.
But here is the secret: the command line isn't harder than a graphical interface; it’s just more direct. Instead of hunting through layers of menus to click a button, you simply tell the computer exactly what you want it to do.