I’ve seen a lot of promising AI prototypes fall apart after launch. And it’s rarely because the model was bad. More often, the problem starts much earlier; teams treat the data layer like something they can figure out later.
They’ll spend weeks fine-tuning prompts, testing models and debating evaluation scores, then throw together the retrieval pipeline over a weekend and move on. At first, everything looks great in demos. But a few months later, the system gives outdated answers; the embeddings no longer match the source documents, and nobody fully understands what changed.
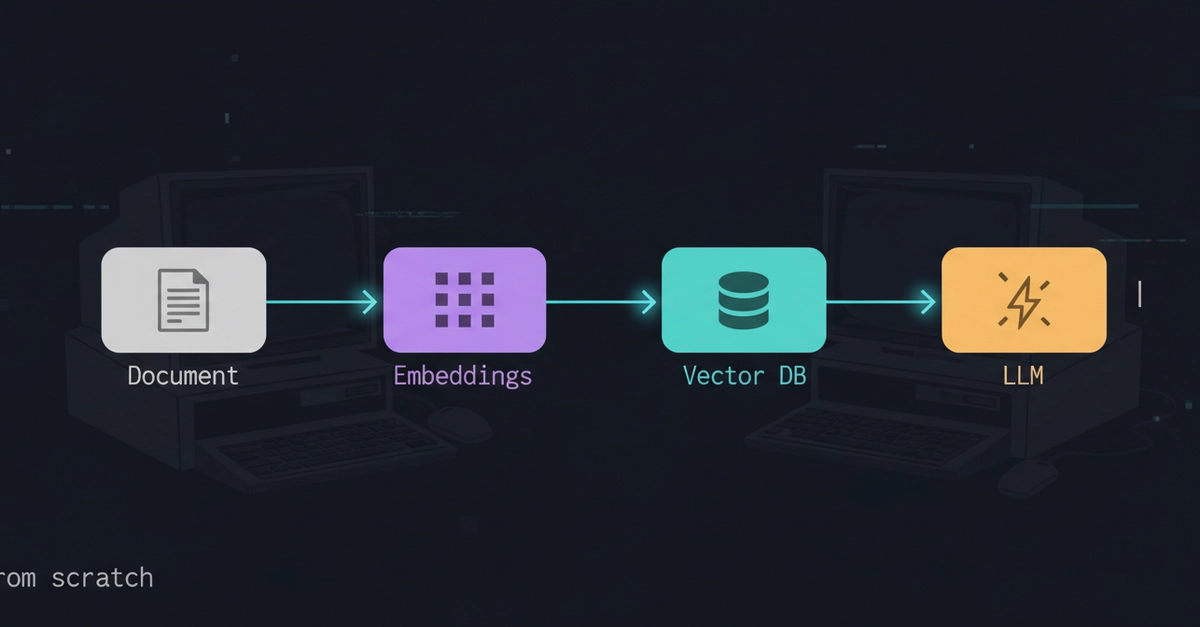
What started as an impressive prototype slowly becomes difficult to trust in production. The teams that avoid this tend to realize one thing early: Embedding pipelines are fundamentally a data engineering problem, not an entirely new AI discipline. It’s still ETL (Extract, Load, Transform) at its core, but with embeddings and vector stores as the destination instead of a warehouse.
Once you start looking at it that way, a lot of things become clearer. Problems like versioning, data freshness, lineage and retries stop feeling “AI-specific.” They’re data infrastructure problems we’ve already spent years learning how to solve.