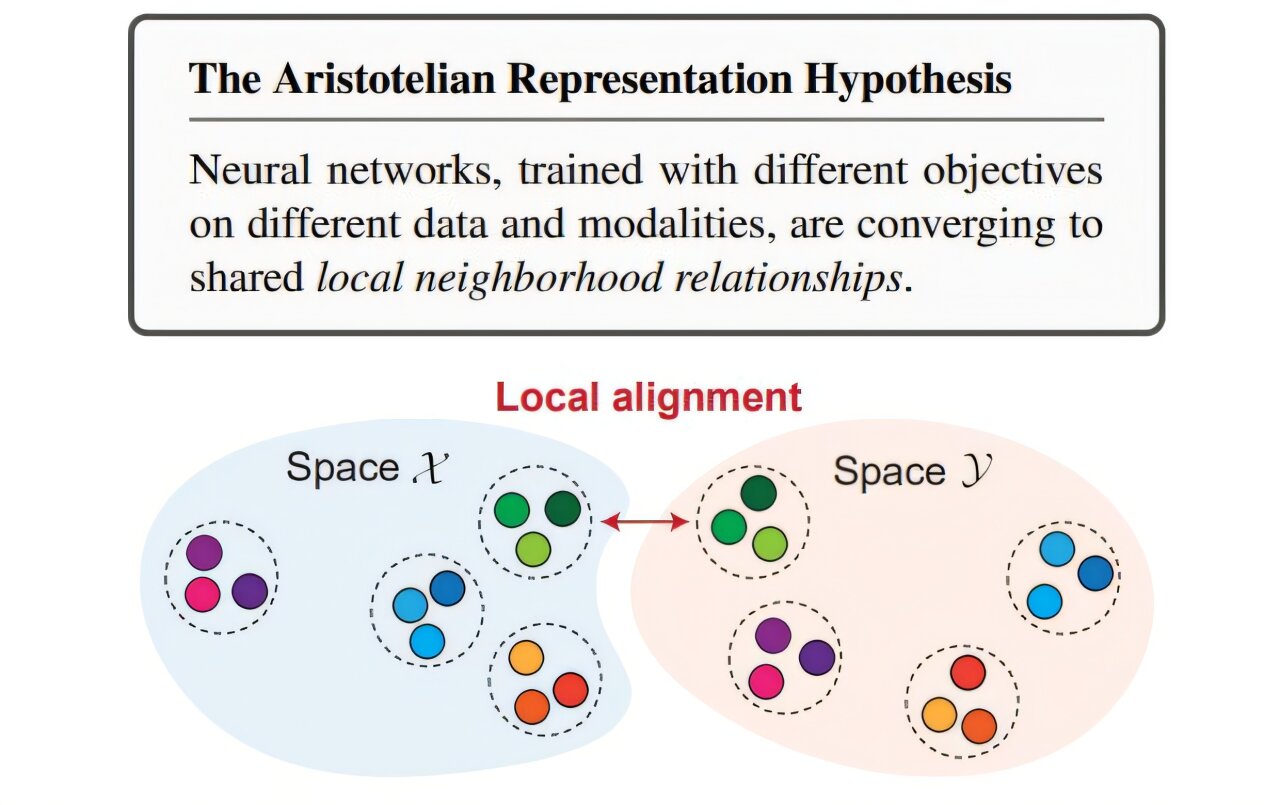
Il y a deux ans, une équipe du MIT avançait une hypothèse provocante : à mesure que les modèles d'IA gagnent en puissance, ils tendent à percevoir le monde de la même manière. Vraiment ? Des scientifiques de l'EPFL démontrent que la réalité est plus nuancée.Les systèmes d’intelligence artificielle actuels apprennent en étant entraînés sur d’énormes ensembles de données. Les modèles linguistiques sont entraînés sur du texte, les modèles visuels sur des images et des vidéos, et les modèles audio sur des données sonores. Pourtant, ces différents types de données s’ancrent souvent dans la même réalité. En 2024, une équipe du Massachusetts Institute of Technology a émis l’idée que, à mesure que les modèles gagnent en capacité, quelles que soient les données sur lesquelles ils sont entraînés (images, texte, vidéo ou audio), leur façon de voir le monde converge. Dans cette représentation platonicienne, à l’instar des formes idéales de Platon, ces systèmes semblaient découvrir la même structure sous-jacente du monde.Cette idée a rapidement fait phosphorer la communauté de l’IA et soulevé des questions essentielles. Si différents systèmes d’IA parviennent indépendamment à la même vision interne de la réalité, cela révèle-t-il quelque chose de fondamental sur l’intelligence elle-même ?Mesurer les distances entre les conceptsDans les systèmes d’IA modernes, des concepts tels que « chien », « voiture » ou « arbre » sont représentés sous forme de vecteurs dans leurs espaces de haute dimension. Pour mesurer la similitude entre les modèles, les chercheuses et chercheurs comparent ces représentations internes en examinant les schémas de distances ou de proximité entre de nombreux concepts. Basés sur ces résultats, les travaux du MIT suggéraient que, à mesure que les modèles gagnaient en capacité, leurs représentations internes s’alignaient de plus en plus d’un système à l’autre, laissant entrevoir une convergence vers une représentation partagée du monde. Mais pour l’équipe de l’EPFL, il manquait quelque chose.Les scientifiques du Laboratoire d’apprentissage automatique pour la biomédecine, rattaché à la Faculté informatique et communications et à la Faculté des sciences de la vie de l’EPFL, ont réexaminé l’hypothèse platonicienne et dévoilé une réalité plus complexe. « L’idée de départ était passionnante », explique Maria Brbic, professeure assistante, responsable du laboratoire et coauteure de l’étude. « Mais nous revenions sans cesse à la même question : que signifiaient réellement ces scores de similarité ? »La réponse dans les mathématiquesDans un article qui sera présenté à l’International Conference on Machine Learning 2026, en juillet, Maria Brbic et ses collègues avancent que la convergence apparente de différents modèles est trompeuse : les modèles ont l’air plus semblables notamment à cause de la manière dont les similitudes sont mesurées. Plus les modèles d’IA deviennent grands et complexes, plus les scores de similarité peuvent naturellement augmenter, même si les modèles n’apprennent pas réellement la même structure sous-jacente du monde. Ces conclusions suggèrent que les systèmes d’IA ne convergent pas vers une représentation universelle unique de la réalité, contrairement à ce que de nombreux scientifiques avaient imaginé.Une partie du problème réside dans les mystérieuses mathématiques des espaces de haute dimension. Dans l’espace tridimensionnel quotidien, le hasard se comporte de manière intuitive. Mais dans les espaces de très haute dimension – du type de ceux utilisés par les réseaux neuronaux modernes – les distances peuvent se « concentrer », ce qui signifie que de nombreux points sans rapport entre eux peuvent finir par être presque à égale distance les uns des autres.« Nous avons puisé des idées dans la géométrie à haute dimension et les avons utilisées pour questionner les mesures de similarité. Beaucoup de choses ont alors commencé à s’effondrer », précise Fabian Gröger, doctorant à l’Université de Bâle et auteur principal de l’article, qui a travaillé en tant que chercheur invité à l’EPFL avec Maria Brbic. Il s’est penché sur ce problème avec Shuo Wen, doctorant au laboratoire MLBio.Fabian Gröger explique :« Nous sommes partis d’une question simple : si l’on prend deux modèles aléatoires totalement indépendants, qui n’ont jamais été entraînés et qui n’ont jamais vu de données, pourquoi une métrique devrait-elle malgré tout indiquer une certaine similarité ? Cela suggère une similitude même lorsqu’il n’y a pas de structure d’apprentissage commune.» « Si deux modèles aléatoires semblent déjà similaires, alors la métrique détecte peut-être une base mathématique plutôt qu’une structure commune significative », complète Maria Brbic.Pour autant, l’équipe de l’EPFL n’a pas conclu qu’il n’existe aucune convergence. Au contraire, elle a constaté qu’un type particulier de similitude restait remarquablement stable : les relations de voisinage local entre les concepts.Concrètement, cela signifie que les systèmes d’IA apprennent souvent que certaines idées vont de pair – les voitures se regroupent près d’autres voitures, les animaux près d’autres animaux, et les concepts apparentés forment des voisinages stables – même si la géométrie globale des modèles diffère considérablement. « Ce qui importe, ce n’est pas nécessairement la structure absolue de l’espace, mais qui est proche de qui », tranche Maria Brbic.Platon contre AristoteEn réponse à cette observation, l’équipe a proposé l’hypothèse d’une représentation aristotélicienne. Alors que Platon mettait l’accent sur les formes idéales universelles, son élève, Aristote, s’intéressait davantage aux relations, aux catégories et au contexte. Pour les chercheuses et chercheurs, cette vision relationnelle décrit mieux la manière dont les systèmes d’IA modernes organisent la connaissance.Cette distinction peut sembler abstraite, mais elle a des implications importantes pour l’avenir de l’IA. L’hypothèse platonicienne avait encouragé l’idée que des systèmes d’IA suffisamment avancés pourraient naturellement converger vers une compréhension commune et stable du monde. Cela a fait naître l’espoir que les systèmes d’IA avancés pourraient devenir plus faciles à comparer, à combiner ou à aligner. Les conclusions de l’EPFL compliquent l’équation.« Nos travaux suggèrent qu’il peut encore exister des différences significatives dans la manière dont les modèles représentent le monde dans son ensemble, résume Fabian Gröger. Cela a une importance pour l’alignement, les systèmes multimodaux et, en fin de compte, la manière dont nous comprenons ce que ces modèles apprennent réellement. »L’étude présente aussi un nouveau cadre d’évaluation de la similarité des représentations qui corrige les biais identifiés par les chercheuses et les chercheurs. L’équipe a testé cette approche sur des modèles linguistiques, visuels et vidéo, et a trouvé des preuves cohérentes d’une convergence locale plutôt que d’un alignement global.Faire avancer la scienceContactée par l’EPFL avant la publication de l’article, l’équipe du MIT à l’origine de l’hypothèse platonicienne a accueilli favorablement ces travaux. « La réponse a été très constructive, se réjouit Maria Brbic. C’est ainsi que la science progresse. On affine les idées, on teste les hypothèses et, petit à petit, on construit ensemble une meilleure compréhension. »Loin de clore le débat, ces recherches soulèvent de nouvelles questions sur ce que les systèmes d’IA partagent exactement et ce qui reste fondamentalement différent entre eux. « Le prochain défi consiste à comprendre précisément quelles structures locales convergent, et si ces connaissances pourraient nous aider à construire des systèmes d’IA plus fiables et mieux alignés », conclut Fabian Gröger.
Les systèmes d'IA se forgent-ils une vision identique du monde?
Il y a deux ans, une équipe du MIT avançait une hypothèse provocante : à mesure que les modèles d'IA gagnent en puissance, ils tendent à percevoir le monde de la même manière. Vraiment ? Des scientifiques de l'EPFL démontrent que la réalité est plus nuancée.
1,150 words~5 min read