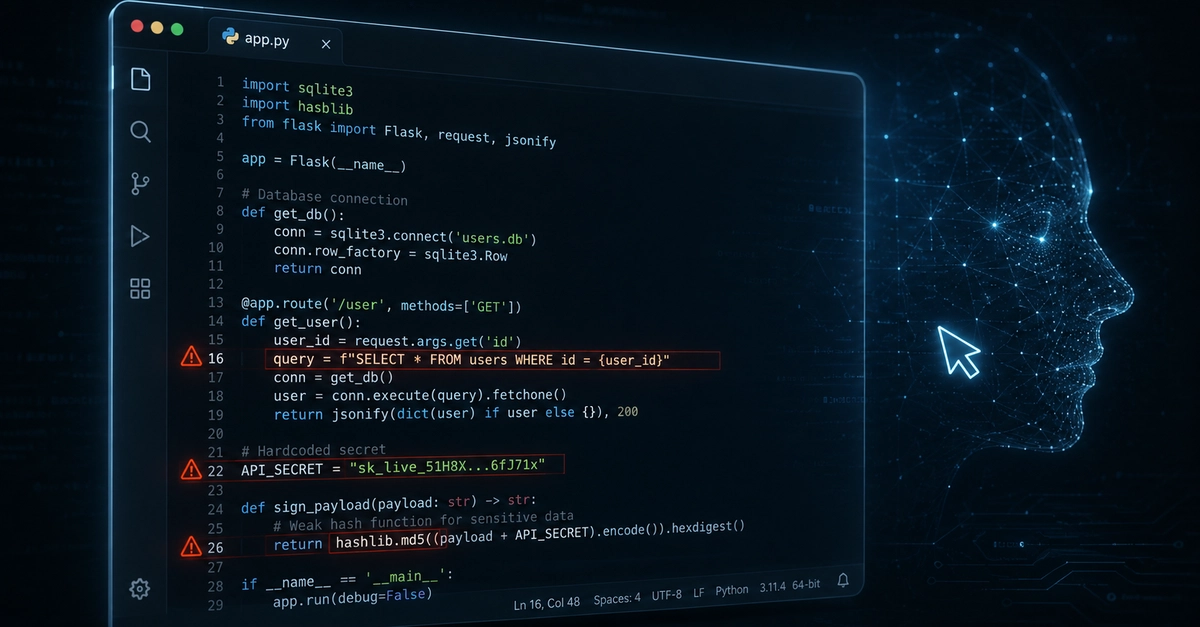
A 2025 benchmark ran three industry static analysis tools (SonarQube, CodeQL, and Snyk Code) against sixty-three real vulnerabilities planted in ten real-world C# projects. The best of them, Snyk Code, finished with an F1 of about 0.55. The worst, SonarQube, landed at 0.26. Then the same researchers ran the same set through three frontier LLMs. GPT-4.1, Mistral Large, and DeepSeek V3 all landed between 0.75 and 0.80, mostly by catching things the static tools just walked past.
If you read that as "AI wins, replace the SAST", you'd be wrong. The same study, and a pile of others like it, show that LLMs win on recall (they catch more) while losing badly on precision. A separate analysis of IDOR detection found that 88% of the issues a popular AI coding agent flagged as IDORs weren't actually IDORs. So you can hand your AI a 50-file pull request, and it'll find the SQL injection you missed. It'll also find six injection bugs that aren't injection bugs, two race conditions that aren't races, and a "potential authorization bypass" in code that has no authorization in it.
That tension is what AI security review really is. You're trading a reviewer that misses confidently for a reviewer that finds things confidently, including things that don't exist. The point of this article is to walk through where that trade pays off across the four classic vuln classes (SQL injection, XSS, auth bugs, unsafe deserialization) and how to wire AI into a security review pipeline so the noise doesn't drown the signal.