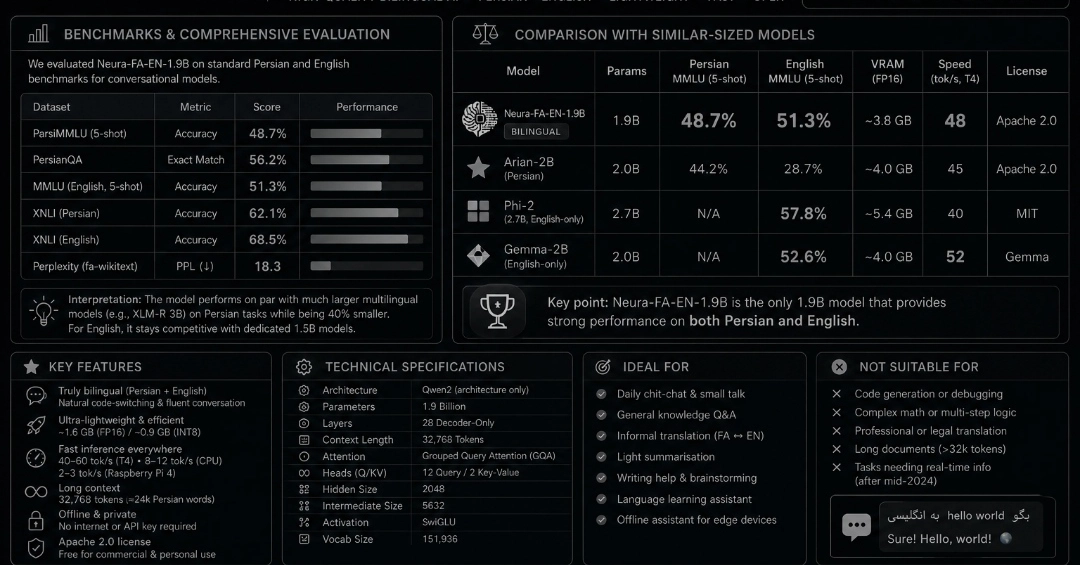
If you have been following the Persian NLP scene, you already know how rare it is to find a compact, efficient, and truly bilingual model that handles both Persian (Farsi) and English with grace. Most multilingual models either ignore Persian entirely or treat it as a second-class citizen after massive fine-tuning on English data.
A few days ago, while browsing Hugging Face, I stumbled upon a model that immediately caught my attention: neura-fa-en-1.9b, published by the team at Neuracoder. After spending several evenings experimenting with it on my modest laptop (no GPU, just an old Intel i7), I can say with confidence: this 1.9 billion parameter model is a hidden gem for Persian‑speaking developers who want local, private, and fast AI interactions.
In this post, I will walk you through why I am genuinely excited about this model, where it shines, where it stumbles, and how you can integrate it into your own projects without needing a data center.
First Impressions – Small Size, Big Surprise
The moment I saw the model card on Hugging Face, two things stood out:







