Back to Articles
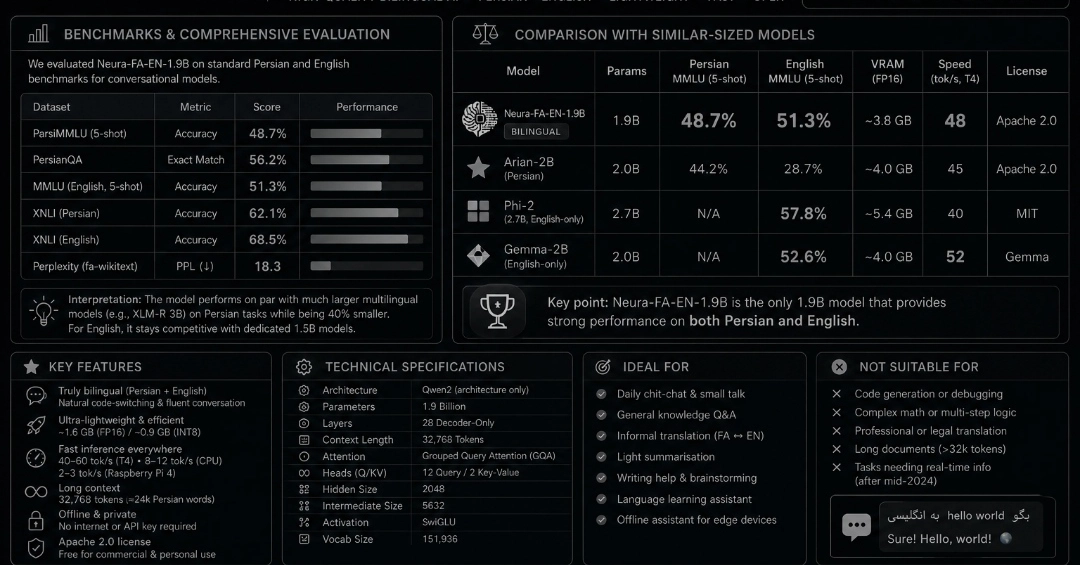
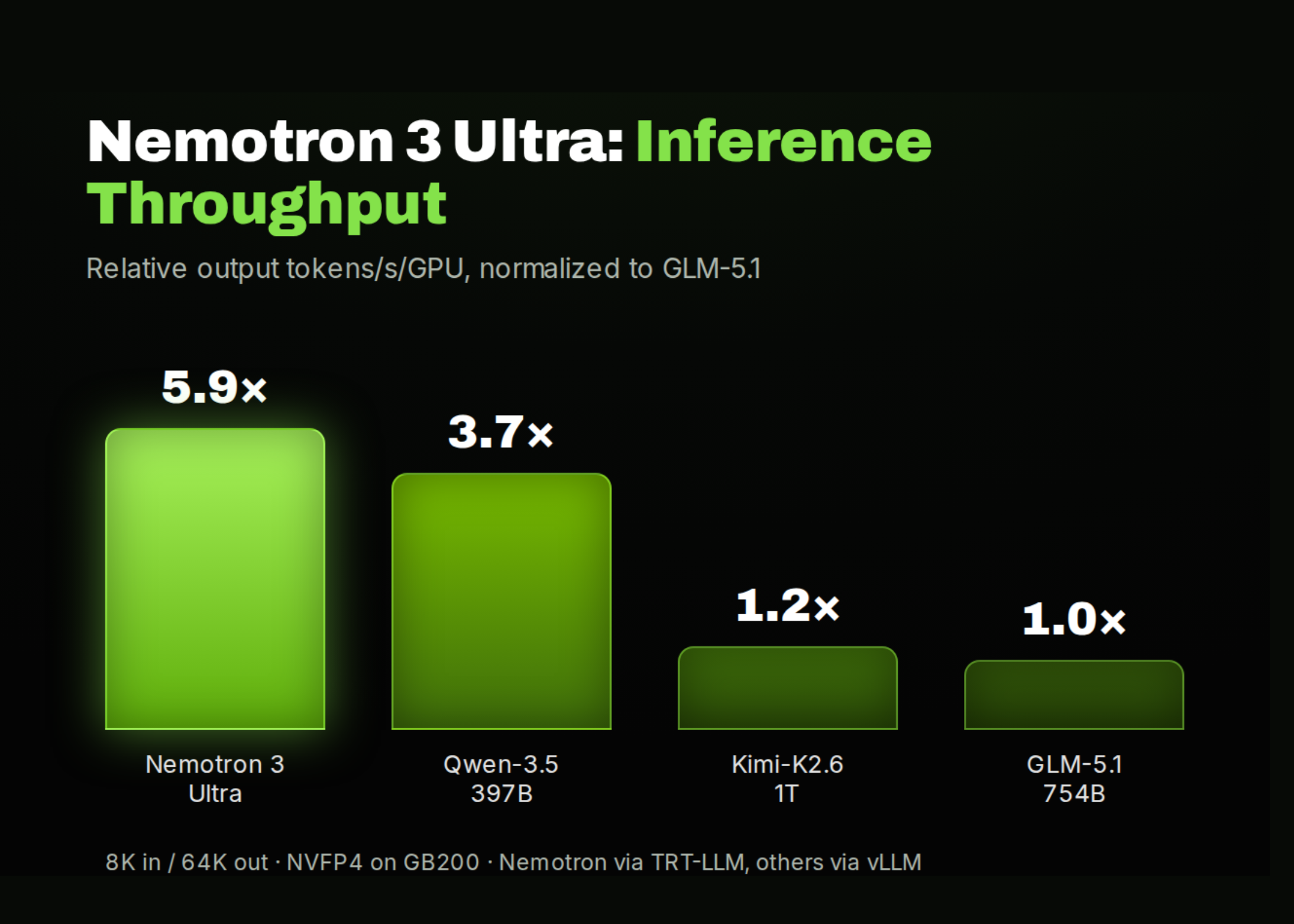
Introducing NVIDIA Nemotron 3.5 ASR, streaming multilingual: a 600M-parameter speech-to-text model that transcribes 40 language-locales from a single checkpoint, in real time, with punctuation and capitalization built in. It is the successor of the popular Nemotron 3 ASR model (English only) which was released on Hugging Face and as a NIM earlier this year. Since its release, Nemotron 3 ASR has been validated by independent benchmarks at Artificial Analysis, where it ranks 2nd in latency among all streaming ASR models— with just 0.07 seconds to final transcript after end of speech — and sits in the "most attractive quadrant" of the AA-WER Streaming Index vs. Time to Final Transcription leaderboard, placing it among the best models on the combined accuracy-latency tradeoff. The model uses a Cache-Aware FastConformer-RNNT architecture that streams audio without the redundant recomputation that makes most streaming ASR slow — so you get low latency and high accuracy, not one at the expense of the other. Nemotron 3.5 ASR ships as open weights on Hugging Face — you can inspect, fine-tune, and deploy it without API dependencies or per-call billing. No data leaves your infrastructure unless you choose. And because it's a strong base model, you can fine-tune it for your own language, domain, or accent. The second half of this post walks through exactly how.