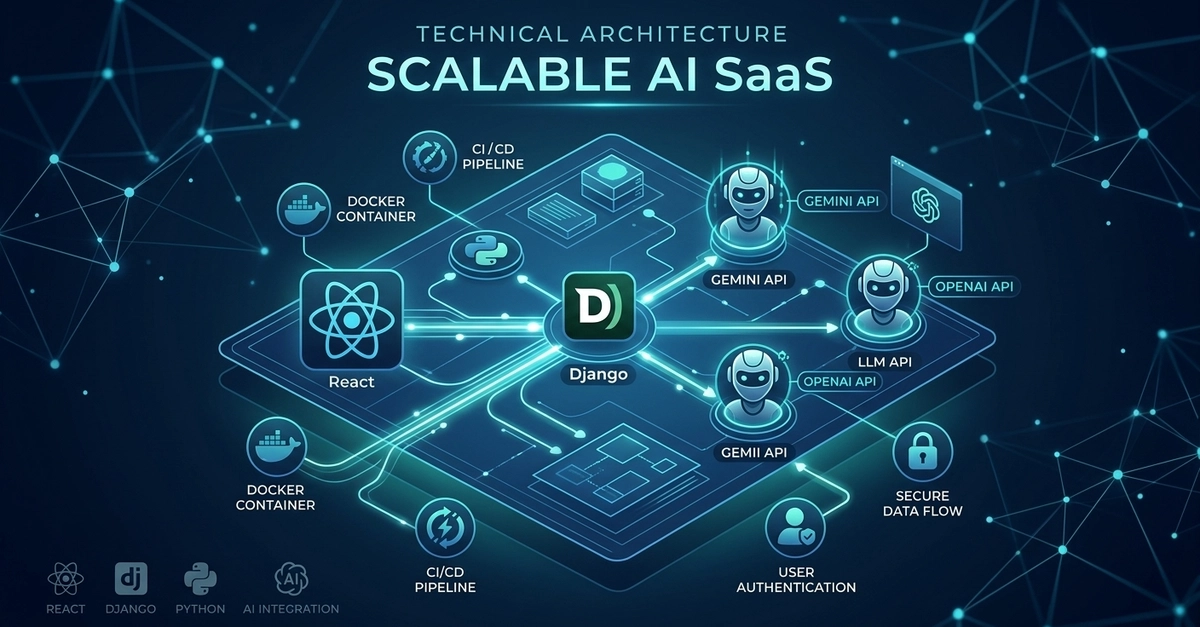
Picking the wrong web framework for your AI backend costs weeks of refactoring — usually when you're already under deadline pressure. In 2026, AI backends have specific requirements: streaming responses, async inference calls, structured input validation, and long-running requests. Here's how FastAPI, Flask, and Django actually hold up.
What an AI backend actually needs
Before comparing frameworks, be precise about the requirements:
Streaming: LLM responses arrive token-by-token. The framework must support Server-Sent Events (SSE) or chunked HTTP without blocking other requests.
Async I/O: Inference API calls — remote or local — take 2–20 seconds. Blocking them in a synchronous thread destroys throughput.