TL;DR
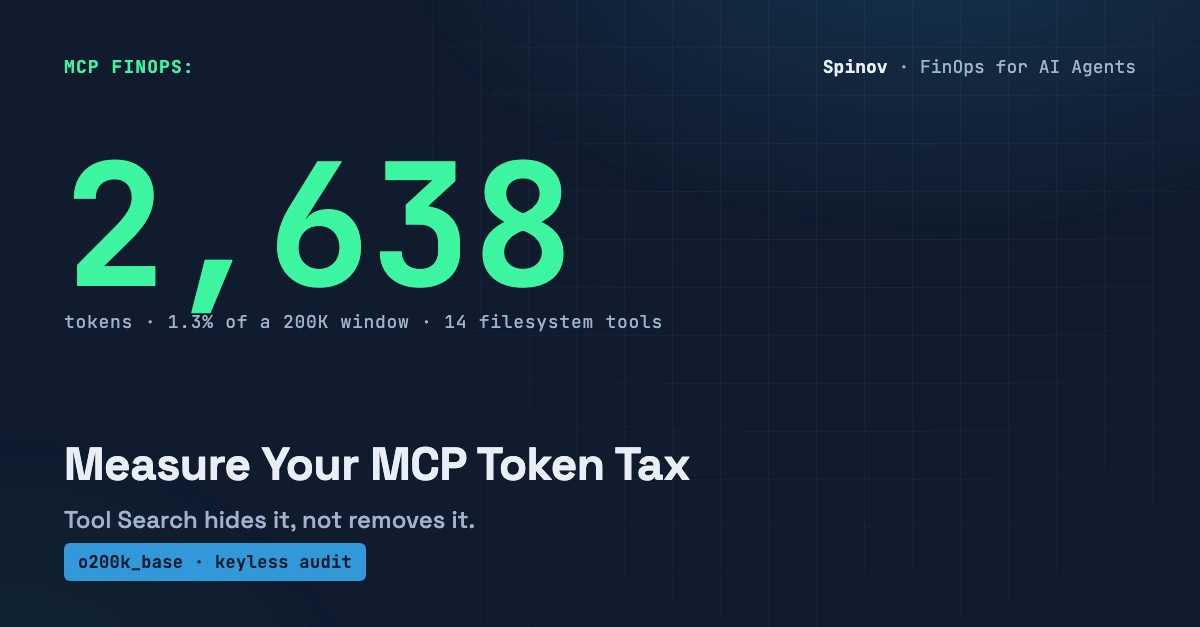
A 200-tool MCP setup burns 150–220k tokens at session start; a two-meta-tool proxy cuts that to ~2,000 tokens — a 98–99% reduction.
At $3/million input tokens and 20 sessions/day, that's $270/month down to $3/month.
The pattern: one discover_tools(query) meta-tool and one call_tool(name, args) meta-tool replace hundreds of schemas at startup, with on-demand retrieval via BM25 + synonym expansion.
A model burning its full context window on schemas before the first message has zero room for conversation history, documents, or reasoning — the real cost is context headroom, not dollars.