TL;DR
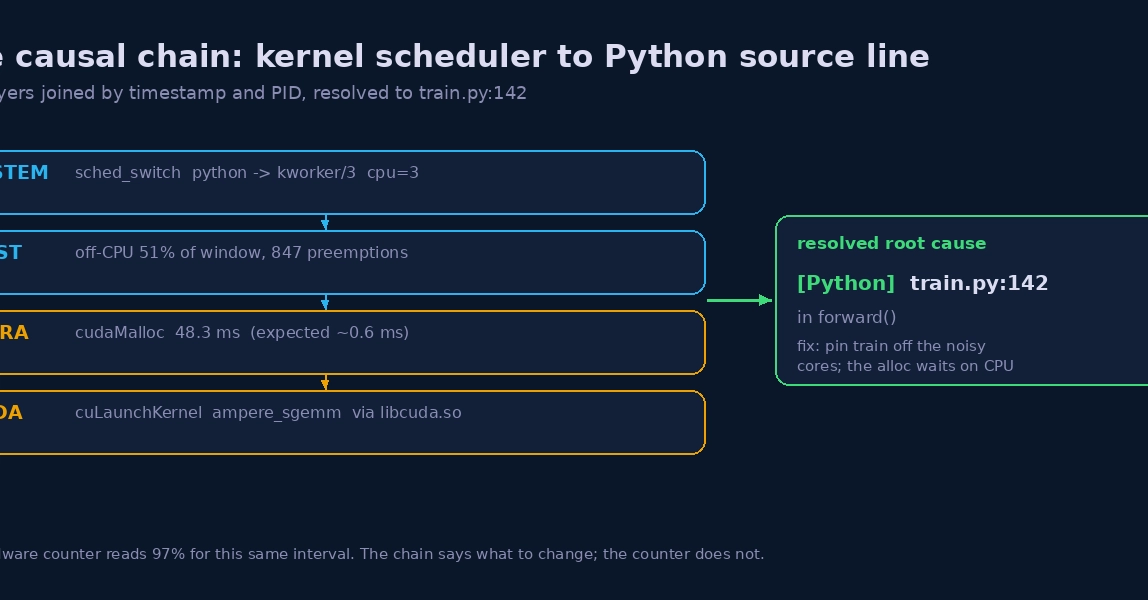
3am page: GPU training pipeline missed its SLA. Datadog shows 95% GPU utilization. nvidia-smi agrees. Everything looks green, but the job is 3x slower than expected. Zero tools to diagnose this. eBPF kernel tracing produces causal chains in 60 seconds: the host CPU was fighting with DataLoader workers, starving the GPU. A taskset fix, back to sleep, no ML engineer woken up. This is a field guide for GPU incident response using eBPF tracing to go from alert to root cause in under a minute.
The 3am Page Every GPU SRE Dreads
GPU incident response starts with a page that makes no sense. PagerDuty fires:
[CRITICAL] GPU Training Pipeline SLA Breached