Google Just Shipped an Encoder-Free Multimodal Model That Runs on Your Laptop
Google dropped Gemma 4 12B yesterday. It hit #1 on Hacker News within hours, and the reason isn't just "another model release." The architecture is genuinely different from anything else in the 10-15B parameter range.
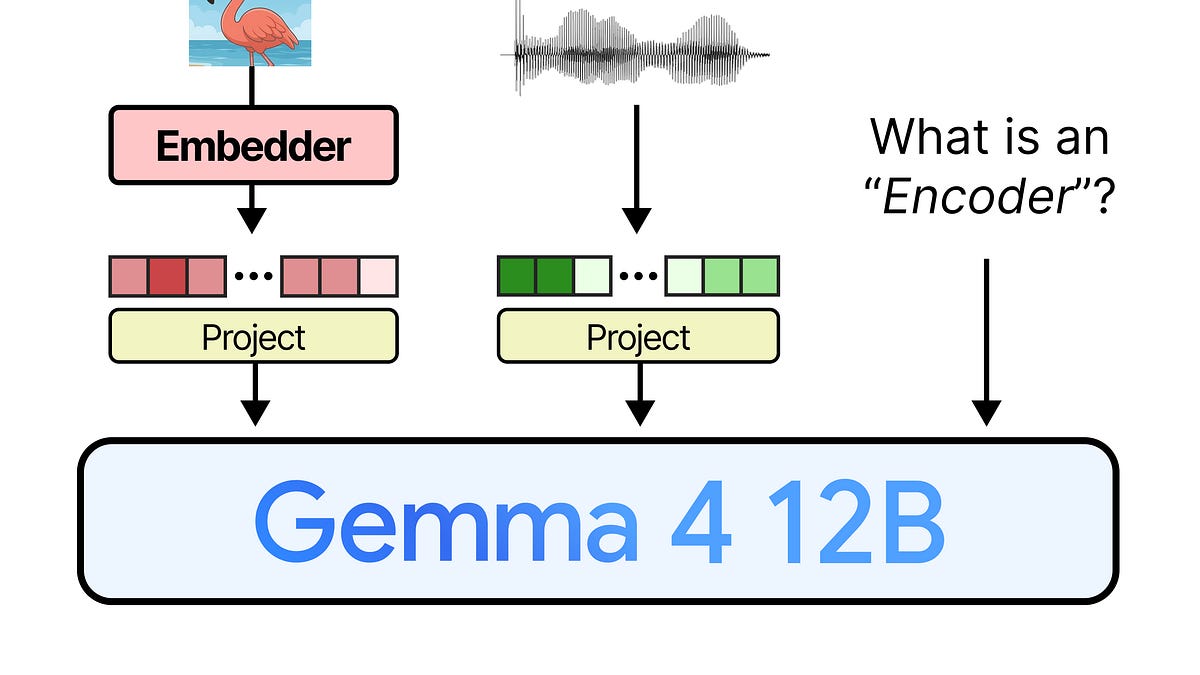
Traditional multimodal models use separate encoders for each input type. Vision goes through ViT or CLIP. Audio runs through Whisper or HuBERT. Then all those encoded representations feed into the LLM backbone. It works, but it's wasteful — every encoder adds memory overhead and inference latency.
Gemma 4 12B throws all the encoders away.
Traditional multimodal models (top) rely on separate encoders for vision and audio. Gemma 4 12B (bottom) feeds raw inputs directly into the LLM backbone.