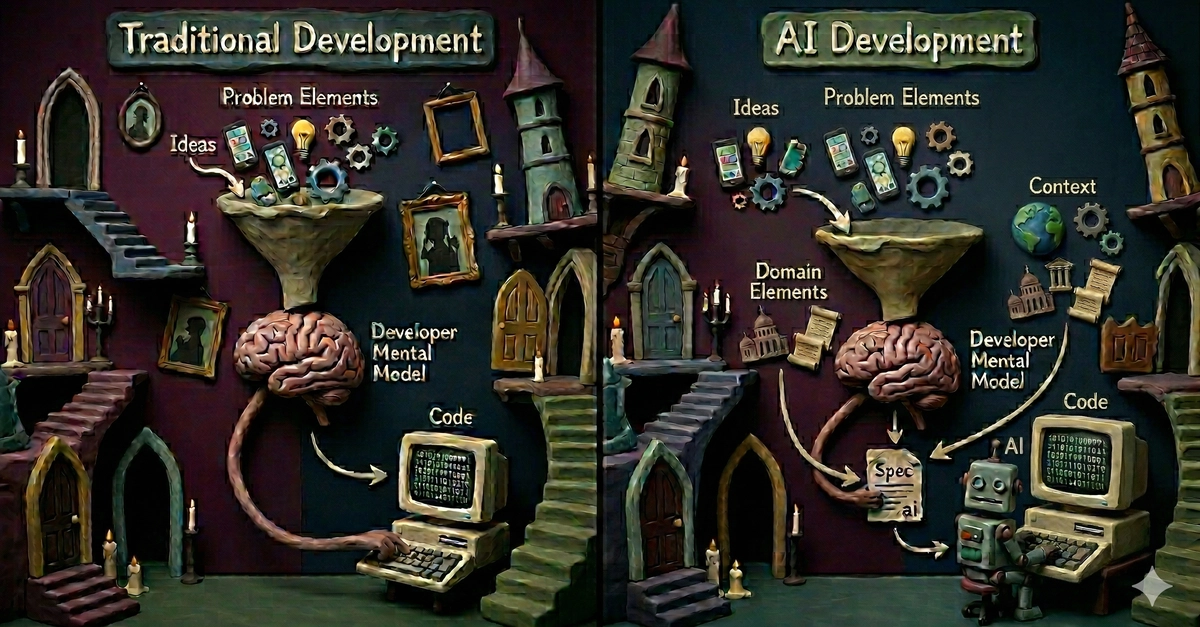
Software is still usually treated as text. We write source files, patch lines, review diffs, and ask tools to infer meaning from syntax. That model works because humans are good at reading convention, context, and intent. It is much less natural for AI systems. A model can produce convincing text while still losing the structure that makes a program correct: types, data flow, control flow, ownership, dependencies, and the relationship between a requested change and the behavior that should be preserved.
DUUMBI starts from a different premise: program meaning should be represented as a typed semantic graph first, with text as a secondary interface. In DUUMBI, program logic lives in JSON-LD graph data. Nodes represent program structure. Edges represent relationships. Stable identifiers let humans and agents point to specific parts of the program without relying on line numbers. The compiler then parses the graph, builds a semantic graph IR, validates it, lowers it through Cranelift, links it with a runtime, and produces a native binary.
That is the core thesis: if software is edited by both humans and AI agents, the durable source of truth should be the program's structure, not just the text that spells it.