How Consistent Hashing Works in Distributed Systems: A Comprehensive Guide
Imagine you're trying to organize a massive library with an infinite number of books, and each book needs to be stored on a specific shelf. As the library grows, new shelves are added, and old ones are removed. You need a system that can efficiently map each book to a shelf, even when the number of shelves changes. This is similar to the problem that consistent hashing solves in distributed systems.
What is Consistent Hashing
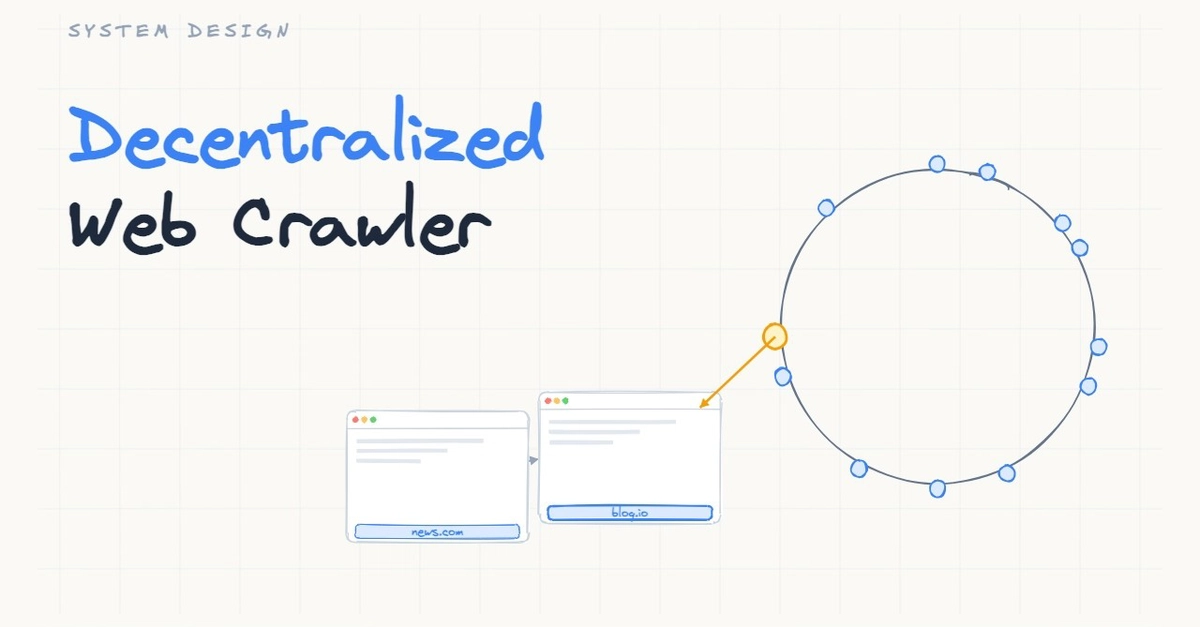
Consistent hashing is a technique used to distribute data across a cluster of nodes in a way that minimizes the number of keys that need to be remapped when nodes are added or removed. It's a critical component of many distributed systems, including caches, content delivery networks (CDNs), and databases. At its core, consistent hashing is a hash function that maps a key to a node in the cluster, while ensuring that the mapping remains relatively stable even when the cluster changes.
Why Consistent Hashing Matters in Distributed Systems