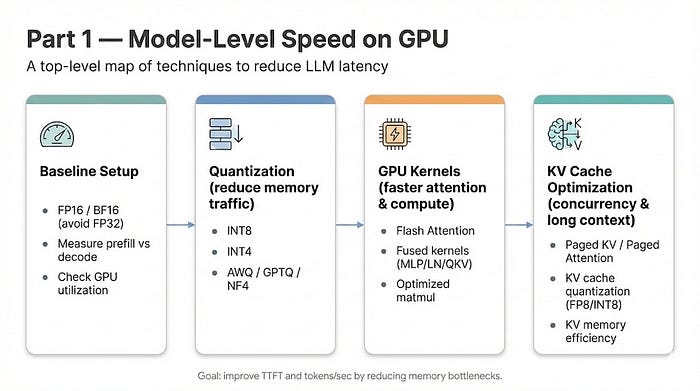
I wrote a post yesterday about why GPUs barely help small text embeddings at batch=1. Different workload, same machines. This time I ran a local LLM inference benchmark across the same three boxes. The result complicated my hardware mental model in a way I think is worth sharing.
The setup
Three machines.
A Mac M2 Pro with 16 GB of unified memory, running Metal through llama-cpp-python.
A Linux desktop with an Intel 13700K, 62 GB of RAM, and an RTX 2080 Ti with 11 GB of VRAM. CUDA 13.