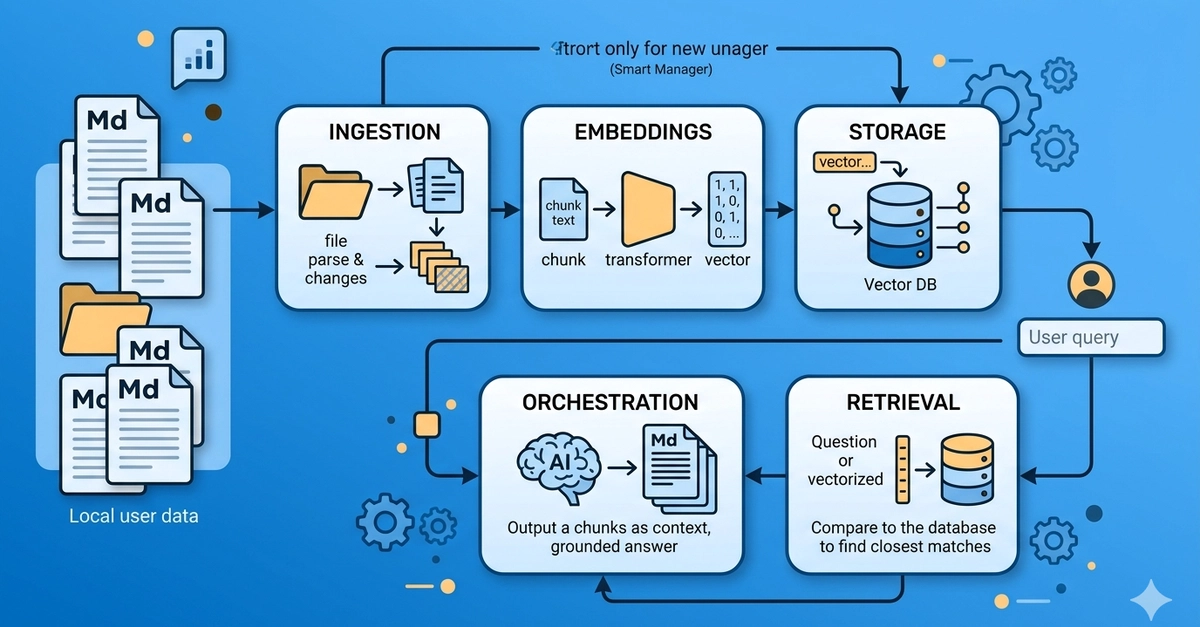
TL;DR
Converting scraped web content directly into Markdown reduces token consumption by up to 90% while preserving the semantic structure needed by LLMs. Combining Markdown extraction with PostgreSQL and the pgvector extension creates a highly efficient, production-ready Retrieval-Augmented Generation (RAG) pipeline without the operational overhead of a dedicated vector database.
The Token Problem in Web-Based RAG
Retrieval-Augmented Generation (RAG) systems are only as good as the context you feed them. When building RAG applications that ingest public documentation, technical blogs, or market reports, the default approach is often to scrape raw HTML, strip the tags, and dump the text into an embedding model.
This approach is fundamentally flawed.