Maker disclosure: I build Macrokit (Apache-2.0, fully open). This is the data, not a pitch — links and the raw runs at the end.
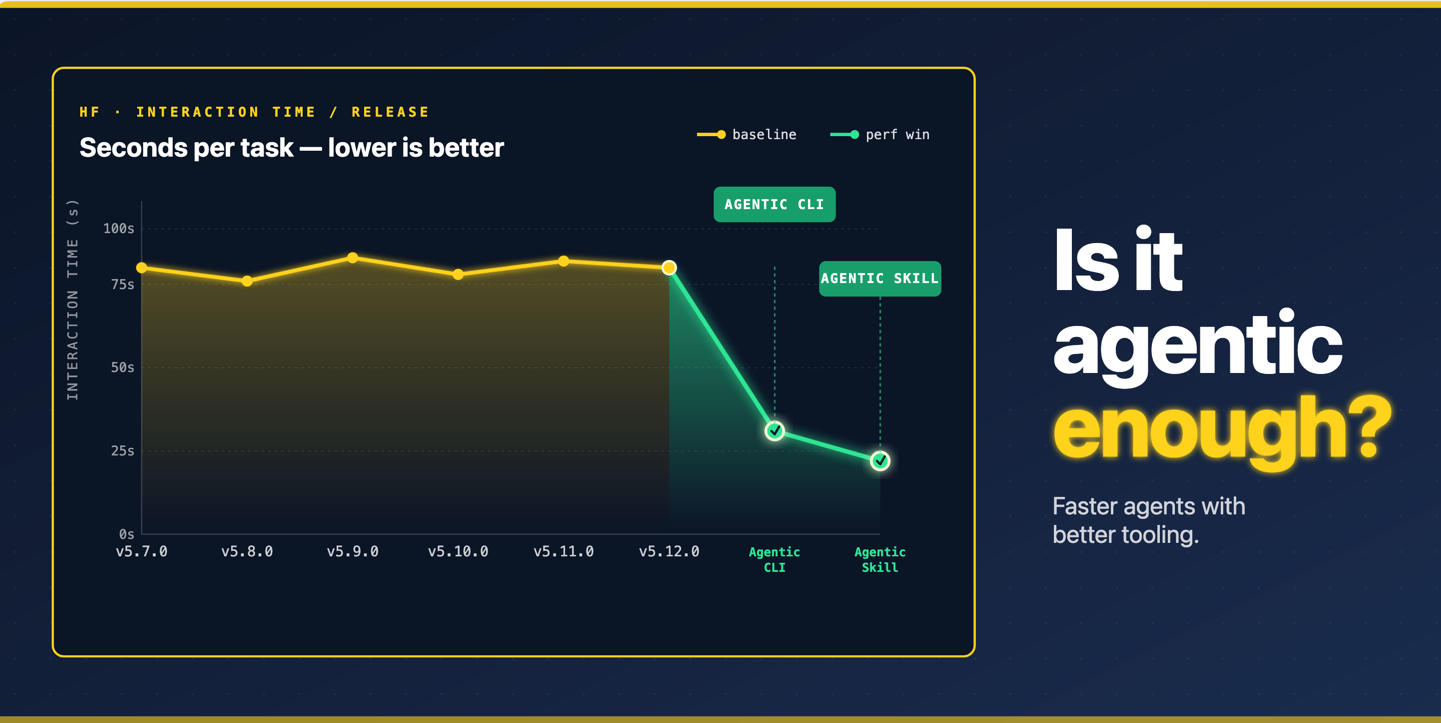
The multi-model benchmark answered: can off-the-shelf local models do real GitHub-maintainer work? (Yes — four of them, 74–82.5% on a pre-registered 100-task corpus.) It didn't answer the more interesting question: why is moving the reasoning to design-time the efficient move, not just a trick? So we ran a direct test — the macro ablation.
Pre-registered and frozen. We committed the whole protocol — the two conditions, the trajectory→intent decode rule, the metric, and the prediction — before running a single MACRO-OFF trial. The git timestamp on bench/MACRO_ABLATION_PREREGISTRATION.md is the audit trail. No post-hoc edits; the pre-registration is frozen. Same committed 100-task corpus, same router and tool-calling machinery, temperature 0; the only thing that changes is the tool set:
MACRO-OFF (reason it live) — the model is given low-level primitives only and must compose the multi-step workflow itself at runtime.
MACRO-ON (the macro) — the workflow is encoded once at design time; at runtime the model only perceives intent and dispatches it in a single routing call.