
I'm building CortexDB — an agent-native context database for AI agents
Most modern RAG systems follow the same pattern:
Split documents into chunks
Compute embeddings
Store them in a vector database
Why AI agents need more than a vector database: Context Packs, AQL, verification, and evidence-aware context.
I'm building CortexDB — an agent-native context database for AI agents
Most modern RAG systems follow the same pattern:
Split documents into chunks
Compute embeddings
Store them in a vector database

Key Takeaways Most SaaS AI agents don't need a vector database — file-based memory plus 1M-token...

Vector databases are almost always talked about in the context of RAG. Store your documents, embed...

For the last year, everyone has been talking about one architecture. RAG. Retrieval-Augmented...

In the rush to build AI agents, we defaulted to complex vector databases. But high-traffic platforms...

Learn what a context engine is, how it fits into agent architecture, where RAG falls short, and how Redis powers the context…
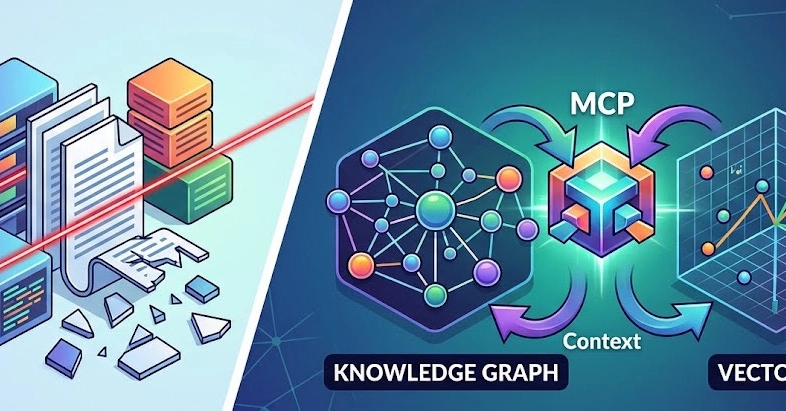
If you have spent any time building AI agents for enterprise use cases this year, you have inevitably...
