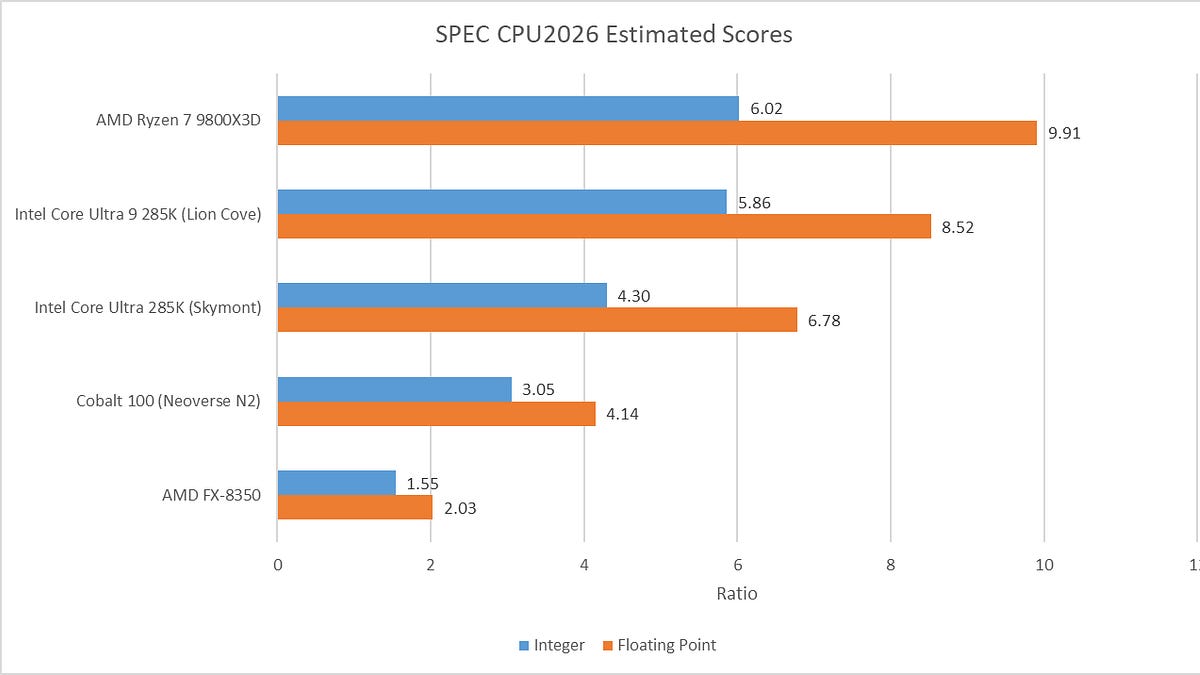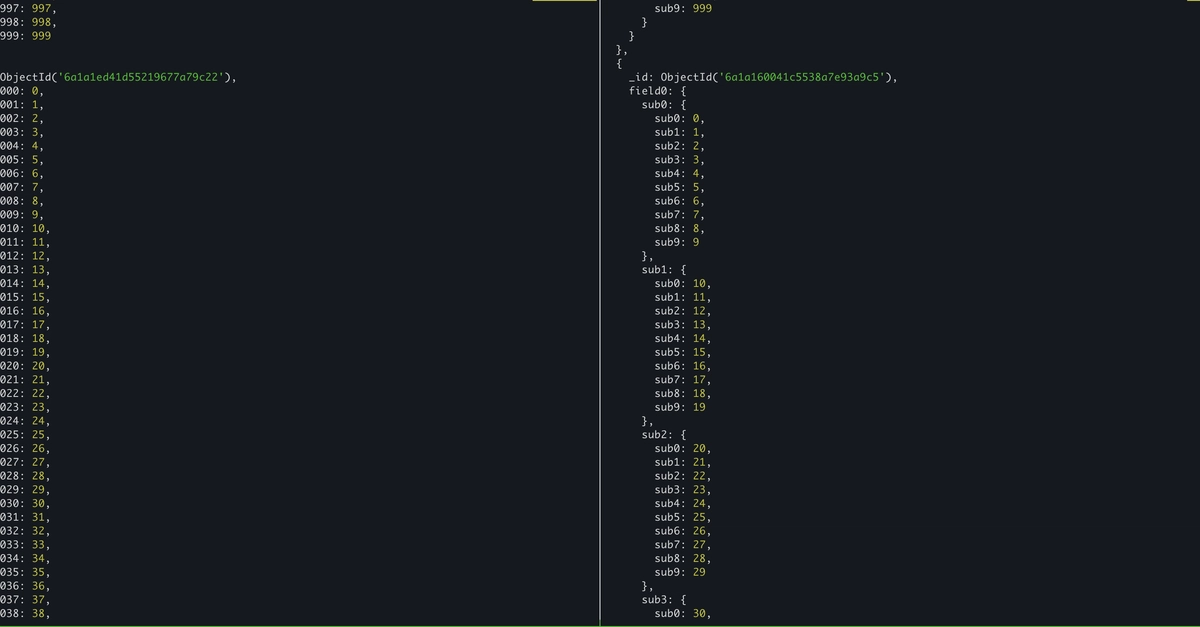
I like vendors benchmarks as they are often good illustrations of worst practice. Rather than focusing on real implementation trade-offs, they pick an extreme case that favors their own implementation by chance but is not optimized in the competitor's — because it is simply not how that technology is meant to be used. For example, Oracle published a "2x" benchmark results using YCSB, a key-value benchmark (slide 14 here), and a "529x" test misusing the raw BSON purpose (here). Both have something in common: they compare a relational database against a document database by using neither technology as it was designed to be used — no normalized tables, no nested documents, just flat key-value fields. The latter test is even worse: it uses 1,000 top-level fields in a single document. Don't do that!
While having thousands of columns in an SQL table is usually undesirable, it's acceptable to have hundreds or even thousands of fields in a document, as they represent multiple entities and value objects. However, nobody creates a flat structure with 1000 top-level fields. The advantage of JSON is its ability to organize entities into nested sub-documents. For instance, instead of storing first_name and last_name as separate fields, you can have a name field containing a sub-object with first and last. During queries, using dot notation to reference name.first and name.last makes no difference with first_name or last_name. It simplifies reading and displaying the document, and, as it is how it should be used, the binary JSON formats are optimized for it.