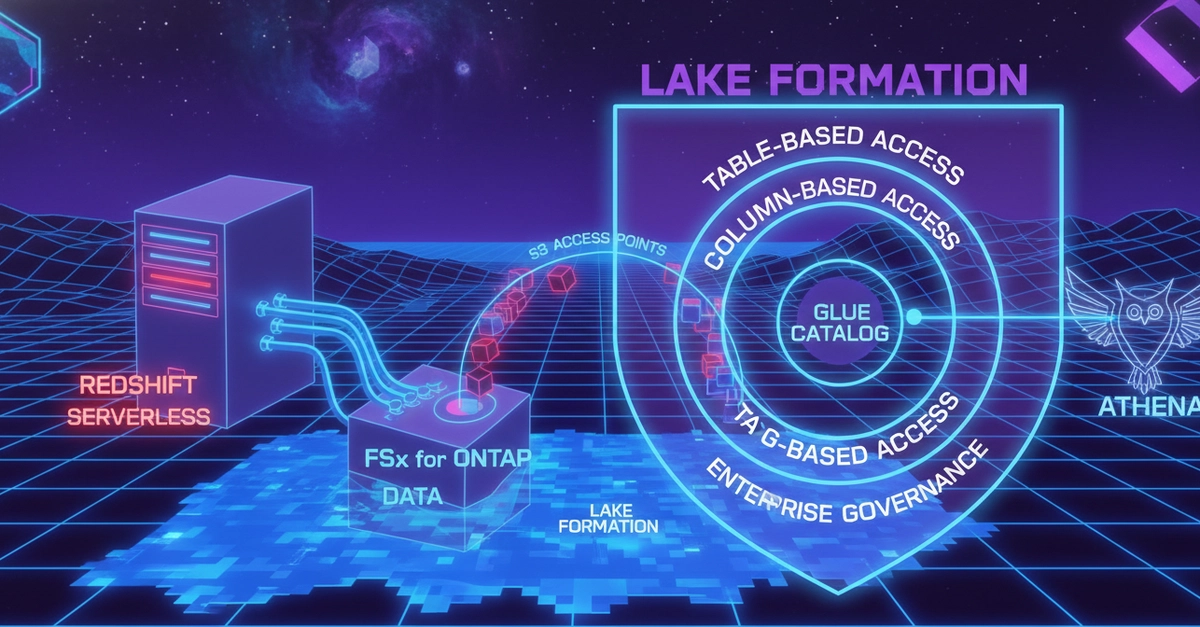
For years, the promise of a cohesive data platform has bumped into the same hard reality: Data lives everywhere. There is data in Snowflake, in AWS Glue, in Microsoft OneLake, in Databricks Unity Catalog, in Apache Polaris™, in homegrown REST catalogs no one fully remembers building.... Every platform came with its own rules, its own metadata, its own gravity. And with each new system, the distance between a common platform and your data grew wider.
The answer isn't to move everything into one place. That ship has sailed. The answer is to connect everything through one layer: a Metadata Hub.
The problem with "just pick one platform"
The conventional wisdom used to be consolidation. Pick a cloud. Pick a catalog. Migrate data and call it done. But the data landscape has moved beyond that vision. Migrating data is counterproductive to AI context. Acquisitions bring new platforms. Teams build on the tools they know. Regulatory requirements demand geographic separation. Multi-catalog/multi-cloud isn't a "mistake." It's the reality that most enterprises live in.
That means metadata fragmentation at a very broad scale. You might know what data you have in Snowflake. But do you know what's in your Glue catalog? Your Unity workspace? Your OneLake instance? Can you query across all of them without copying data? Can you govern them from a single policy? Can you see, in real time, everything your data estate contains?