Public At
International Conference on Learning Representations (ICLR) 2025
最近在找論文的 idea 剛好找到這篇,發表在 ICLR 2025,不過被 Reject 了有點可惜
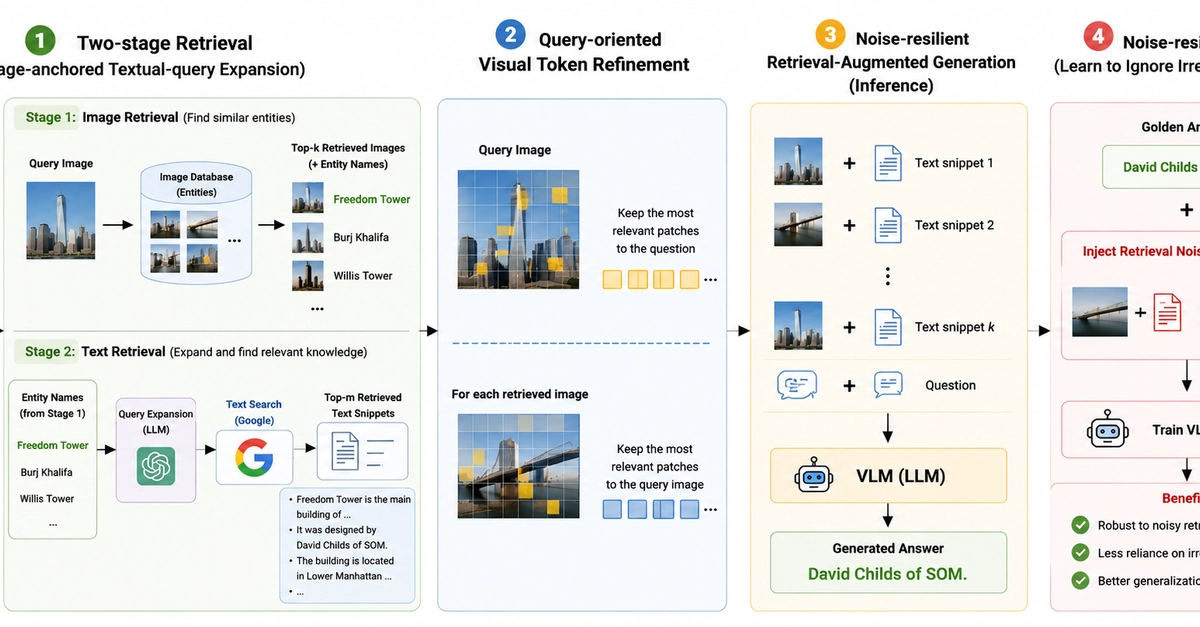
這篇主要是把 RAG 應用到 VLM ,讓模型在回答問題時可以利用外部知識
在很多 VQA 的任務中,答案其實不在圖片裡面,而是需要額外的背景知識
Public At International Conference on Learning Representations (ICLR) 2025 💡 Why I read...
Public At
International Conference on Learning Representations (ICLR) 2025
最近在找論文的 idea 剛好找到這篇,發表在 ICLR 2025,不過被 Reject 了有點可惜
這篇主要是把 RAG 應用到 VLM ,讓模型在回答問題時可以利用外部知識
在很多 VQA 的任務中,答案其實不在圖片裡面,而是需要額外的背景知識

A Blog post by Manuel Faysse on Hugging Face

Introduction: The Place of Large Models in RAG and Lingering Questions Retrieval-Augmented...

Retrieval-Augmented Generation has been powering a large number of question-answering chatbots with...

Vision Language Models (VLMs) offer the exciting possibility of processing text as rendered images, bypassing the need for…

Originally published at vivekpatil23.hashnode.dev The Problem With Naive RAG Nobody Talks About Most...

Explore common challenges and practical solutions for RAG retrieval systems at scale.