Every token your agent spends on file I/O is wasted reasoning capacity.
I was building a document processing agent — the kind that reads incoming research reports, extracts key findings, and produces executive briefings. Nothing exotic. The kind of workflow thousands of teams are automating right now.
The PDF I was testing with was 2MB. Dense text. A typical industry research report.
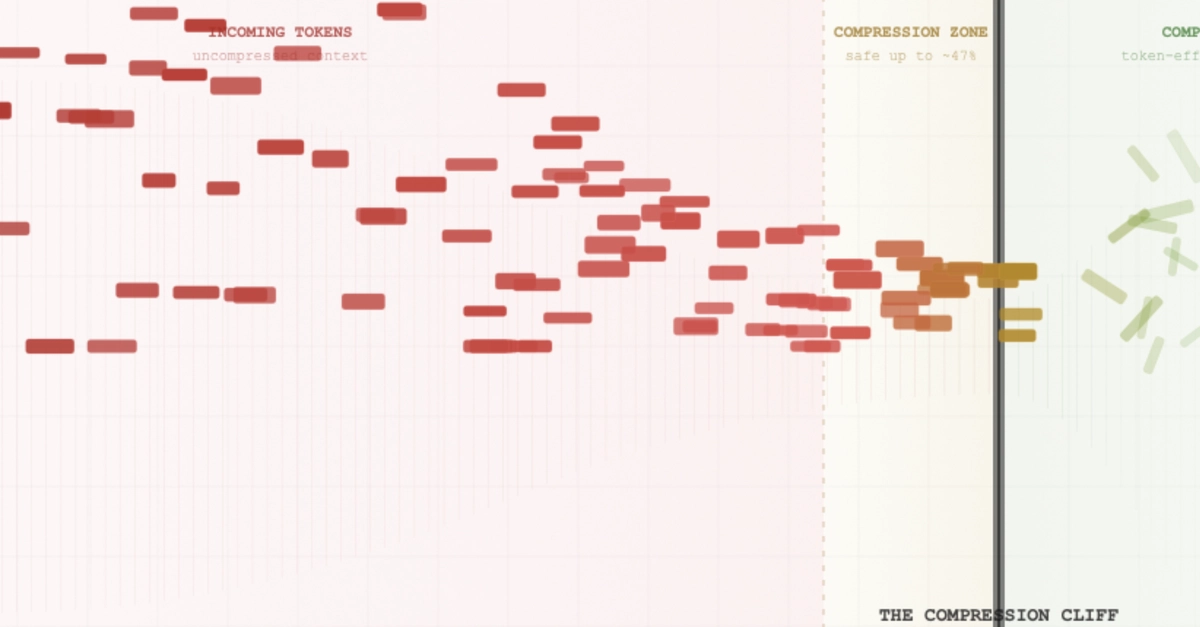
When I measured the token cost of processing it inline, the number was 97,354 input tokens — just to get the text into Claude's context. At claude-sonnet-4-6 pricing, that's $0.29 per document. For a pipeline that processes 500 reports a month, you're looking at $150/month before your agent writes a single word of output.
That's the problem nobody talks about in the AI agent space. Everyone optimises prompt engineering and output tokens. The silent cost is input: the files, the content, the raw data you're shoving into context before the agent can do anything useful.