This post was co-authored with Karan Singh, Head of Partnerships at LangChain
Validating AI agent behavior before production is one of the hardest problems in applied AI. Agents are non-deterministic, multi-step where errors in early steps can affect downstream results. A single bad tool call can cascade through an entire workflow. LangSmith on AWS gives you the evaluation framework to catch these issues early, track them in production, and continuously improve your agent’s reliability throughout its lifecycle.
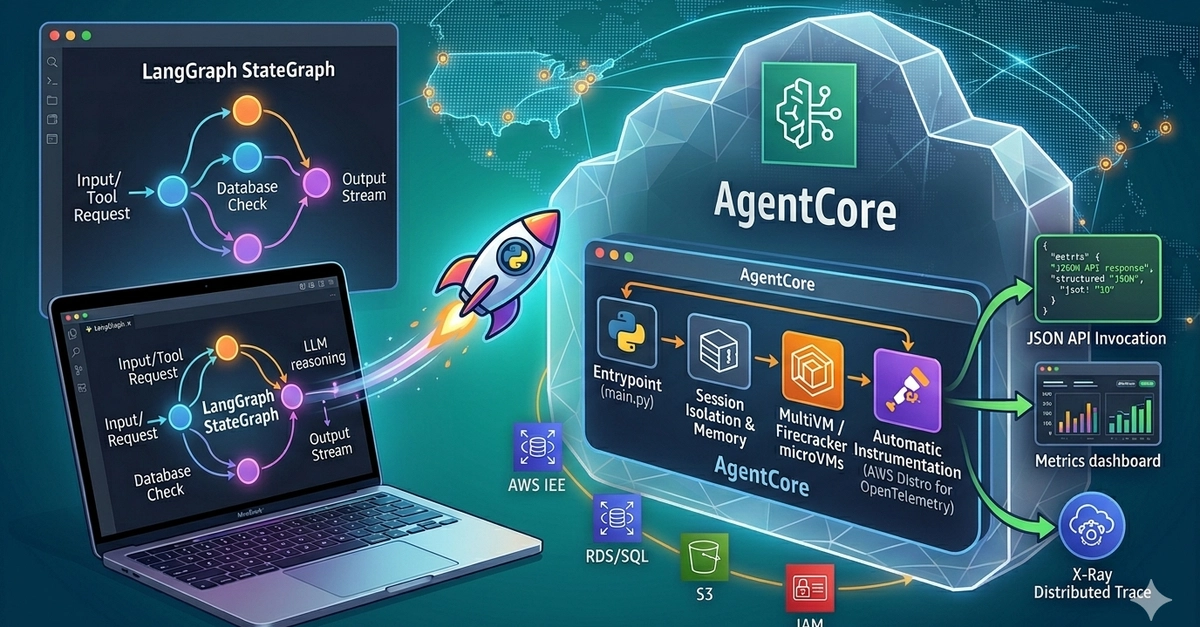
This post combines learnings from LangChain’s work on evaluating deep agents and Anthropic’s guide to demystifying evals for AI agents into a practical guide. In this post, you will learn how to: 1) apply five evaluation patterns for deep agents, 2) build offline evaluations using pytest and LangSmith, and 3) configure online monitoring for production. The walkthrough uses a text-to-SQL deep agent with Amazon Bedrock for the full development to production lifecycle.
Amazon Nova 2 Lite is a fast, cost-effective reasoning model available in Amazon Bedrock. It supports extended thinking with configurable budget levels (low, medium, high) and accepts text, image, video, and document inputs with a 1 million-token context window. Nova 2 Lite handles instruction following, function calling, and code generation well, which makes it a good fit for agentic workloads like the text-to-SQL agent in this post.