The Whisper Becomes a Shout: OpenAI's GPT-5.5 Admission
For weeks, the feeling has been undeniable, a persistent murmur on developer forums and social media threads. Users felt it in the model's responses—a subtle degradation, a digital brain-fog. Code suggestions were less insightful. Creative prompts yielded blander, more repetitive text. The AI just seemed… lazier. What had been a community-wide whisper has now become a shout, amplified not by a leak or a whistleblower, but by the company itself.
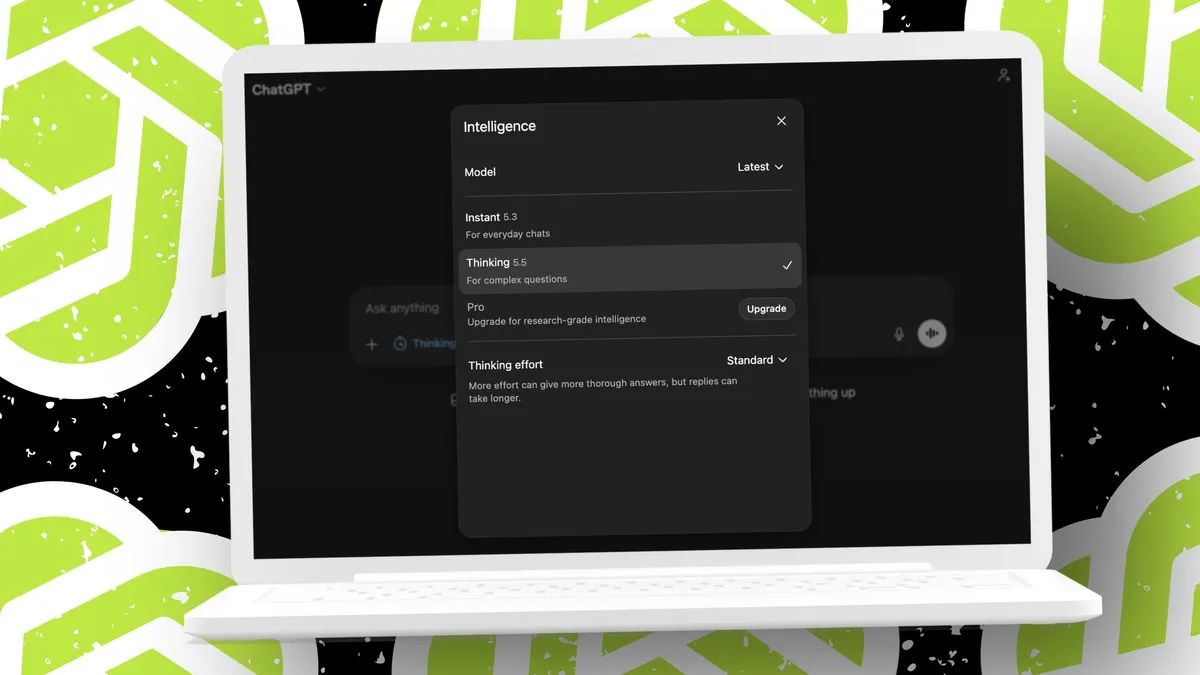
The confirmation came quietly, tucked away where many might miss it. In what can only be described as a startling moment of transparency, OpenAI’s own documentation acknowledged the very issue users were reporting. As highlighted in a report on the discovery, the documents contained solid evidence of "diminished intelligence" in recent updates to its flagship model, GPT-5.5. The official acknowledgment validated the frustrations of thousands, confirming that the perceived performance drop wasn't just a collective illusion. The magic, it seems, had faded slightly, and the magician was finally admitting it.
This admission lands in a complex and often contradictory landscape of AI performance metrics. Just as the community was processing this news, a new, highly specialized benchmark for software engineering, DeepSWE, crowned GPT-5.5 as its top performer. The report from Venturebeat shows the model blowing away its competition in complex coding tasks.