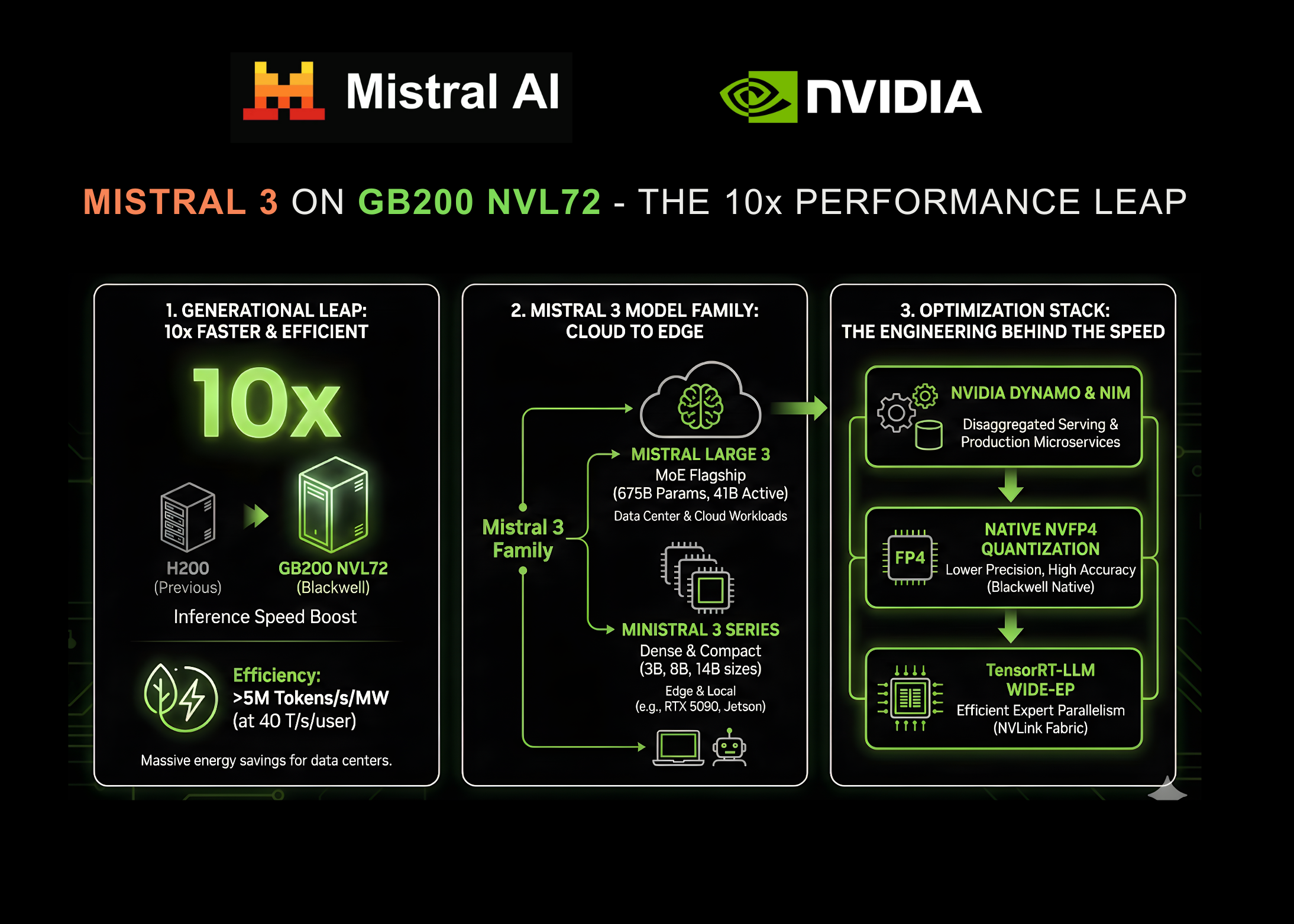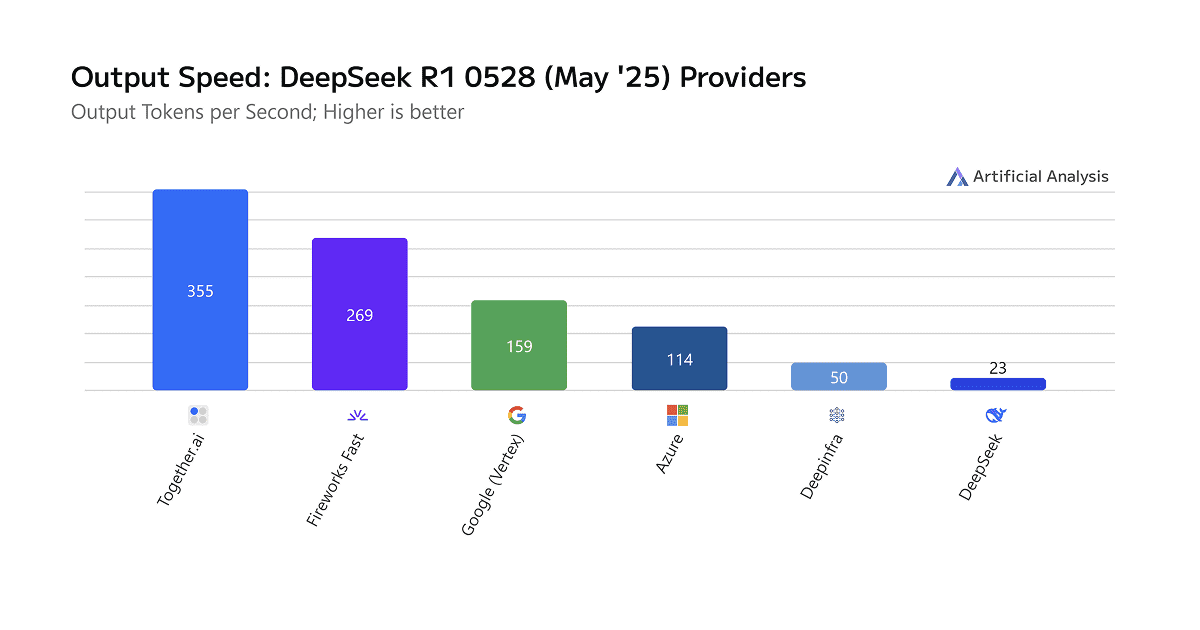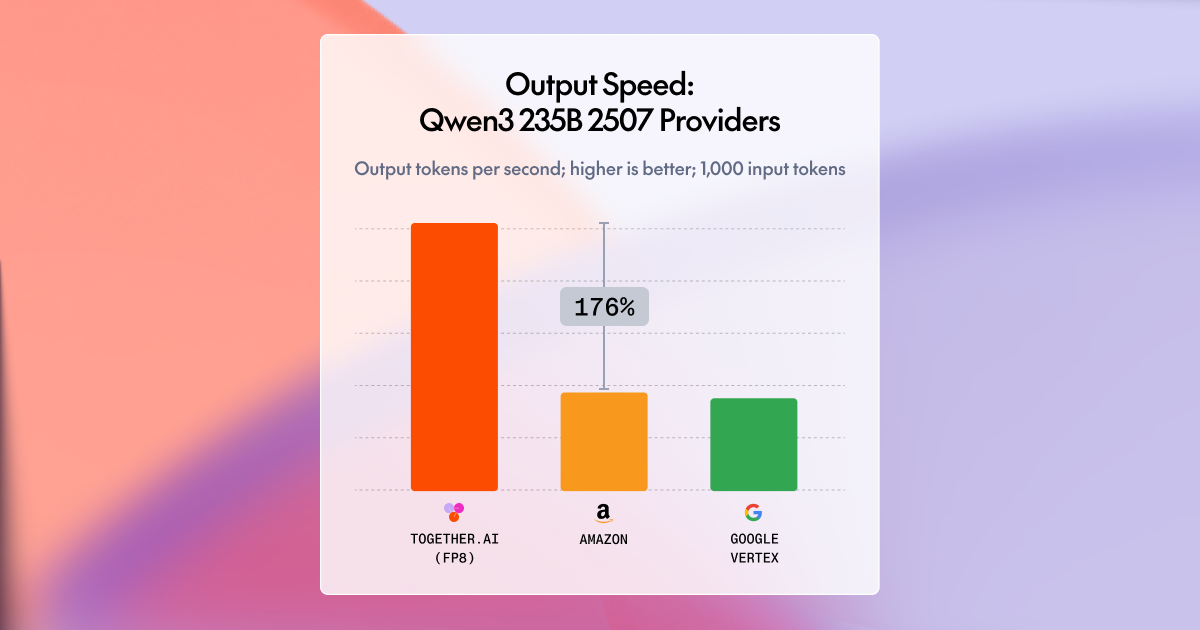
Together AI achieves fastest inference for leading open-source modelsTogether AI now delivers up to 2x faster serverless inference for demanding open-source LLMs, ranking #1 in output speed benchmarks. The performance breakthrough comes from coordinated improvements across next-gen GPU hardware, optimized kernels, near-lossless quantization, and production-grade speculative decoding with custom-trained draft models. Key innovations include architecture-aware calibration, adaptive acceptance strategies, and scalable training pipelines supporting models up to 1T+ parameters — delivering breakthrough speed for models like GPT-OSS, Qwen3, Kimi-K2, DeepSeek-R1, and DeepSeek-V3.1.Over the past few months, our team has been laser-focused on one goal: making our inference platform the fastest place to run the world’s best open-source models. Today, we're excited to share results that speak for themselves.Across multiple independent benchmarks from Artificial Analysis, our platform now consistently ranks #1 in output speed among GPU-based providers for the most demanding open-source models — including GPT-OSS-20B, GPT-OSS-120B, Qwen-3-235B-Instruct, Qwen-3-Coder-480B, Kimi-K2-Instruct, DeepSeek-R1, and DeepSeek-V3.1. On several models, we’re now delivering up to 2x better output speed than competing providers.GPT-OSS-20B: Nearly 2x faster than the next fastest providerGPT-OSS-120B: Nearly 10% faster than the next provider.Qwen3-235B-2507: Over 2.75x faster than the next fastest provider.Qwen3-Coder-480B: Over 22% faster than the next fastest provider.Kimi-K2-0905: Over 65% faster than the next fastest provider.DeepSeek-V3.1: Over 10% faster than the next fastest provider.DeepSeek-R1-0528: Over 13% faster than the next fastest provider.Performance at this level doesn’t come from a single change — it’s the result of coordinated improvements across hardware, kernels, runtime engine tuning, speculative decoding, and draft model training pipeline. In this post, we’ll share the story behind how we achieved it.1. Next-gen GPU hardware with engine optimizationA major portion of our performance gains comes from a fully modernized inference engine built to exploit the latest GPU hardware, optimized kernels, and emerging low-bit quantization formats such as FP4. Instead of optimizing isolated layers, we re-architected the entire stack — compute kernels, memory layout, execution graphs, and scheduling — to work together as a unified high-efficiency system.Hardware-aware execution on the latest GPUsOur engine is tuned specifically for the NVIDIA Blackwell architecture, including the NVIDIA GB200 NVL72. This includes optimized paths for low-precision compute (FP8, FP4), high-bandwidth data movement, and near-zero-overhead scheduling that maximizes utilization across all compute tiers. We don’t just run on fast hardware — we structure execution around it to extract its full capability in real workloads.Together KernelsWe built and integrated a new generation of high-performance GPU kernels designed for NVIDIA Blackwell architecture, enabling us to fully leverage massive bandwidth. This includes our optimized FlashAttention-4 kernels, fused MoE kernels that combine routing and expert FFNs, and more. Together, these hardware-aware kernels dramatically improve throughput for large models and are a key driver of the performance uplift we now see across real-world workloads.2. Turbo optimization suiteQuantizationA key part of our speed gains comes from our ability to quantize large model weights to low-bit formats — FP8, FP4 (nvfp4 or mxfp4), and hybrid precision — while remaining effectively lossless in practice. Our pipeline performs architecture-aware calibration, fine-grain block-wise scaling, and selective mixed-precision on sensitive paths, allowing us to retain target-model quality even at extreme compression levels. Combined with a runtime built for low-bit execution — including fused FP4/FP8 kernels, quantized KV-cache, and Blackwell-optimized memory layouts — we achieve major latency and throughput improvements without sacrificing accuracy. This near-lossless quantization capability is foundational to the faster inference speeds we now deliver across the largest open-source models.Speculator algorithmOne of the biggest unlocks for our recent performance leap has been our work on production-grade speculative decoding algorithms.Speculative decoding is not new, but making it reliable across data domains and consistently faster in a multi-tenant serverless environment is extremely difficult. Our implementation includes:Training-efficient algorithms that enable us to get higher performance per training flopsTraining high-accuracy draft models optimized specifically for each target modelAdaptive acceptance strategies that maximize speed while preserving output qualityFail-safe fallback mechanisms that keep latency predictable under loadThis unlocks substantial gains — especially for models like Kimi or Qwen3, where our SpecDec stack provides nearly double the output speed. Check our ATLAS blog and the world’s fastest Blackwell inference for more details.Large-scale speculator trainingTo support the largest modern LLMs, we built a fully scalable draft-model training pipeline. This is the backbone that lets us deploy high-quality speculative decoders for models that do not come with off-the-shelf speculators, as well as improving upon existing speculators.Our company developed:Scalable training framework that supports high-performance speculator algorithms for target models as large as 1T parameters and beyondCurriculum-based training, post-training recipe, and data-mixing strategies for draft models to match the target model’s stylistic and structural outputsAlignment evaluation framework to test and iterate draft model quality with respect to target modelsHigh-performance architectures and pre-trained base models that can be adapted as speculators for many target modelsThe result: draft models that achieve high acceptance rates and speed, resulting in the world’s fastest inference speed on NVIDIA Blackwell architecture.What’s next?We’re committed to making open-source AI models not only accessible, but also leading performance and planet-level scalability. These latest benchmarks are a milestone — but not the finish line.We’re already working on:Even faster generation for downstream domainsNew generation strategies beyond speculative decodingExpanded support for hybrid quantizationAnd of course, continuing to push inferencing performance forward.Contact usIf you are interested in exploring NVIDIA GB200 NVL72 or other Blackwell GPUs for your workloads — or would like to learn more about how our world-class inference optimization works — we invite you to get in touch with our Customer Experience team.
Together AI delivers fastest inference for the top open-source models
Together AI achieves up to 2x faster inference for top open-source models like Qwen, DeepSeek, and Kimi through GPU optimization, advanced speculative decoding, and FP4 quantization—ranking #1 in speed benchmarks on NVIDIA Blackwell architecture.
906 words~4 min read