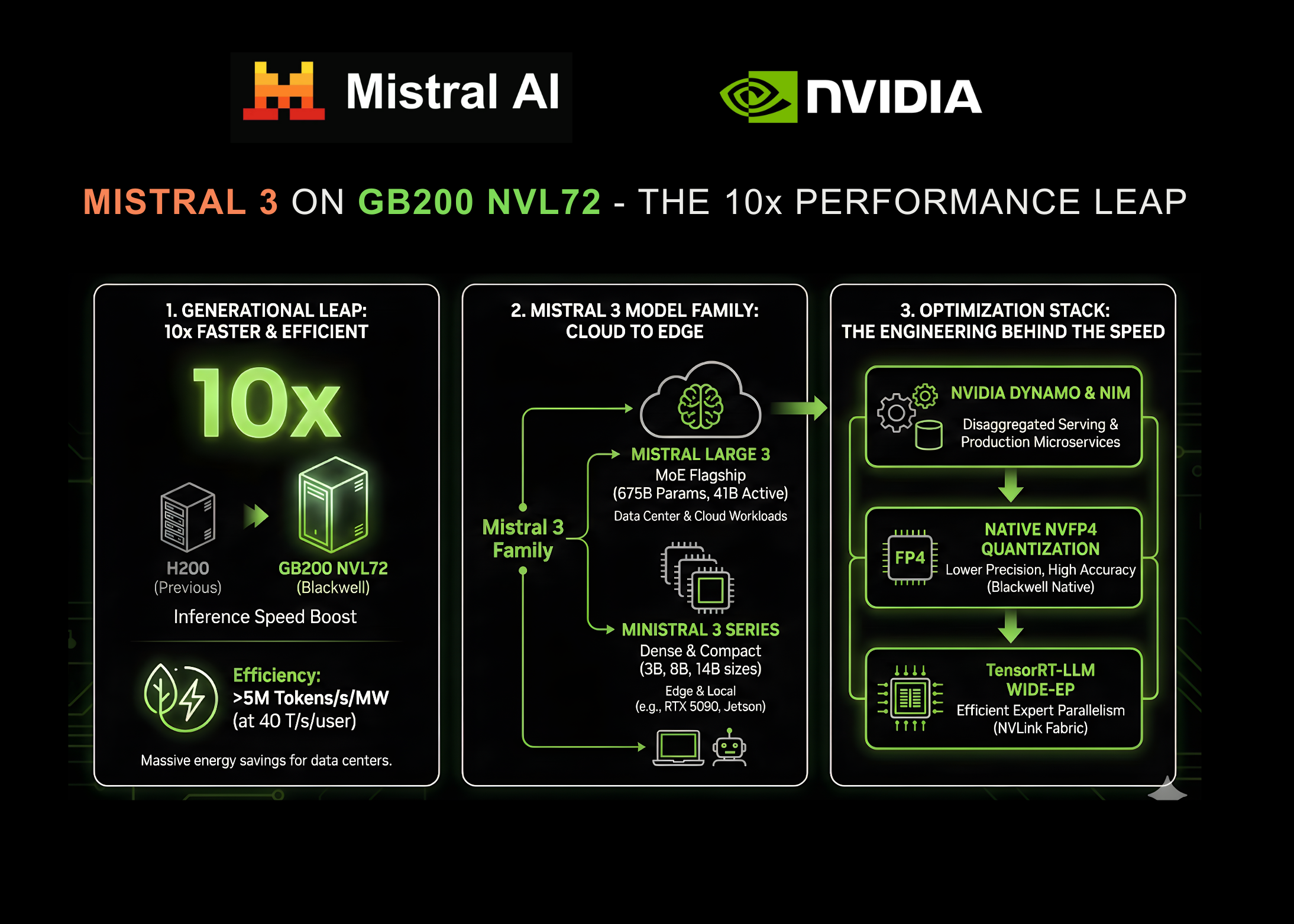
NVIDIA announced today a significant expansion of its strategic collaboration with Mistral AI. This partnership coincides with the release of the new Mistral 3 frontier open model family, marking a pivotal moment where hardware acceleration and open-source model architecture have converged to redefine performance benchmarks.
This collaboration is a massive leap in inference speed: the new models now run up to 10x faster on NVIDIA GB200 NVL72 systems compared to the previous generation H200 systems. This breakthrough unlocks unprecedented efficiency for enterprise-grade AI, promising to solve the latency and cost bottlenecks that have historically plagued the large-scale deployment of reasoning models.
As enterprise demand shifts from simple chatbots to high-reasoning, long-context agents, inference efficiency has become the critical bottleneck. The collaboration between NVIDIA and Mistral AI addresses this head-on by optimizing the Mistral 3 family specifically for the NVIDIA Blackwell architecture.
Where production AI systems must deliver both strong user experience (UX) and cost-efficient scale, the NVIDIA GB200 NVL72 provides up to 10x higher performance than the previous-generation H200. This is not merely a gain in raw speed; it translates to significantly higher energy efficiency. The system exceeds 5,000,000 tokens per second per megawatt (MW) at user interactivity rates of 40 tokens per second.





