By Vilius Vystartas | May 2026
Every LLM can write code that works. The question is: can they write code that's efficient — and does telling them to be efficient actually help?
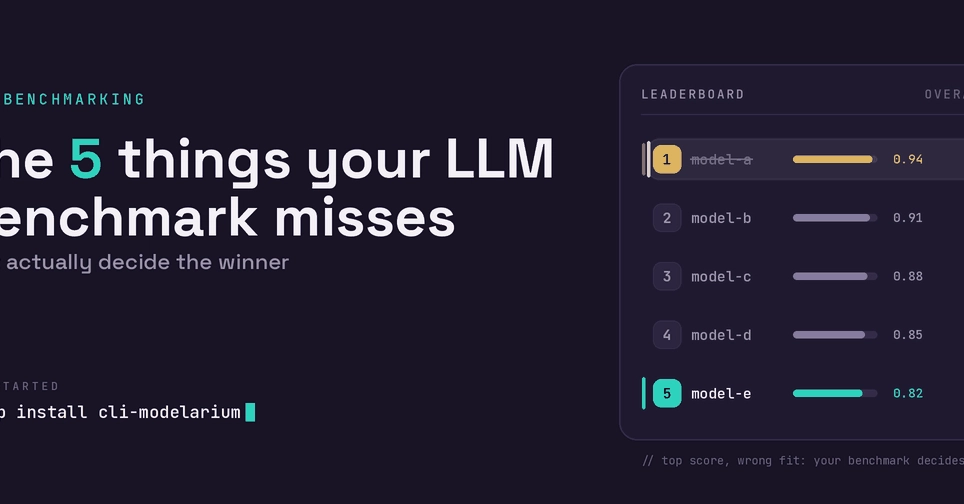
I tested 10 models on 10 coding tasks, each in two phases: unprompted (the model writes its own code) and prompted (explicitly told to write clean, DRY, efficient code). That's 200 API calls, $0.56 total. The results are... not what most prompt engineers would predict.
GPT-5.4 was the only model where prompting gave a substantial boost (+0.20). For most models, the "write efficient code" prompt was meaningless or actively harmful.
How the Metric Works