Training a 107-billion-parameter AI model is hard enough when you have a warehouse full of cutting-edge GPUs connected by ultra-fast networking. Doing it across decentralized clusters on a standard 1 Gbps network? That’s a fundamentally different engineering challenge. 0G Labs claims to have pulled it off.
The project, completed in July 2025 in partnership with China Mobile, represents the first successful decentralized training of an AI model exceeding 100 billion parameters. The research paper detailing the methodology was published on arXiv on June 26, 2025, under the code arXiv:2506.21263.
How DiLoCoX actually works
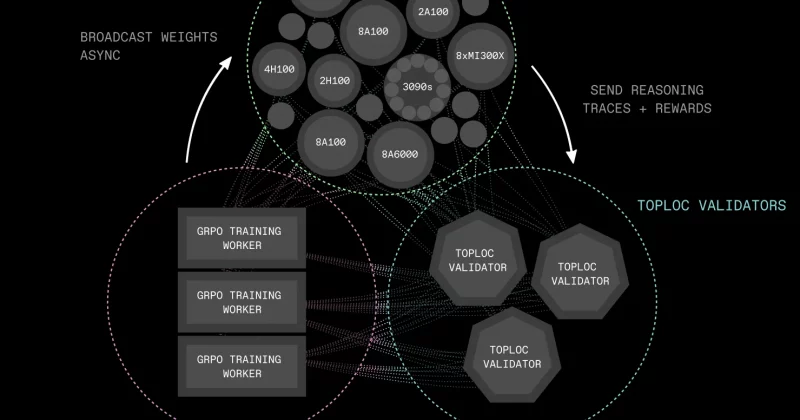
The standard approach, known as AllReduce, requires all nodes to constantly share gradient updates with each other. DiLoCoX instead lets clusters of NVIDIA A800 GPUs work semi-independently, synchronizing far less frequently.
The framework employs several technical innovations to make this possible. Pipeline parallelism breaks the model into stages that can be processed sequentially across devices. A dual optimizer policy uses different optimization strategies for local and global training steps. One-step-delay overlap allows computation to continue while synchronization happens in the background. And adaptive gradient compression squeezes down the data that needs to travel between clusters.