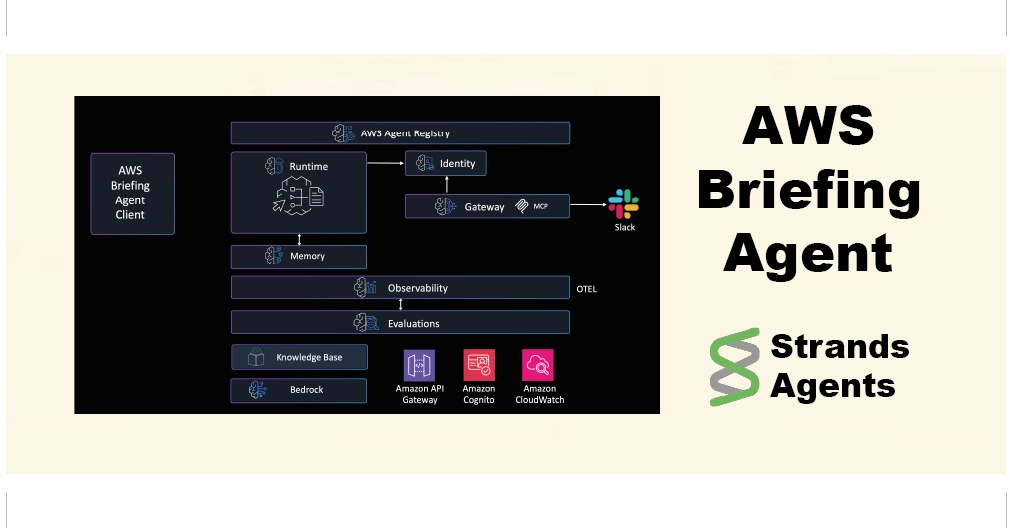
Building high-performance generative AI agents requires architecture that can deliver fast inference, coordinate multiple agents, and operate reliably under production workloads. If you are building generative AI agents to automate reviews, power digital assistants, and support complex decision-making workflows, you need these agents to perform well. They must reduce manual effort, respond in near real time, and scale to thousands of interactions without additional infrastructure management. In this post, you’ll learn how to build these high-performance agents on AWS by combining GPU-accelerated inference, serverless orchestration, shared memory, and built-in observability. These capabilities are essential when moving from experimental prototypes to systems that deliver consistent business value.
As agent workloads grow in production environments, inference latency can increase significantly under concurrent requests, leading to slower responses and degraded user experience. Stateless execution environments often cause agents to lose conversational or task context between interactions. This results in repeated work or inconsistent outputs. Limited visibility into agent execution makes it difficult to diagnose failures, understand reasoning paths, or control operational costs. These challenges become more pronounced in multi-agent systems, where several agents must run in parallel, share context, and aggregate results.