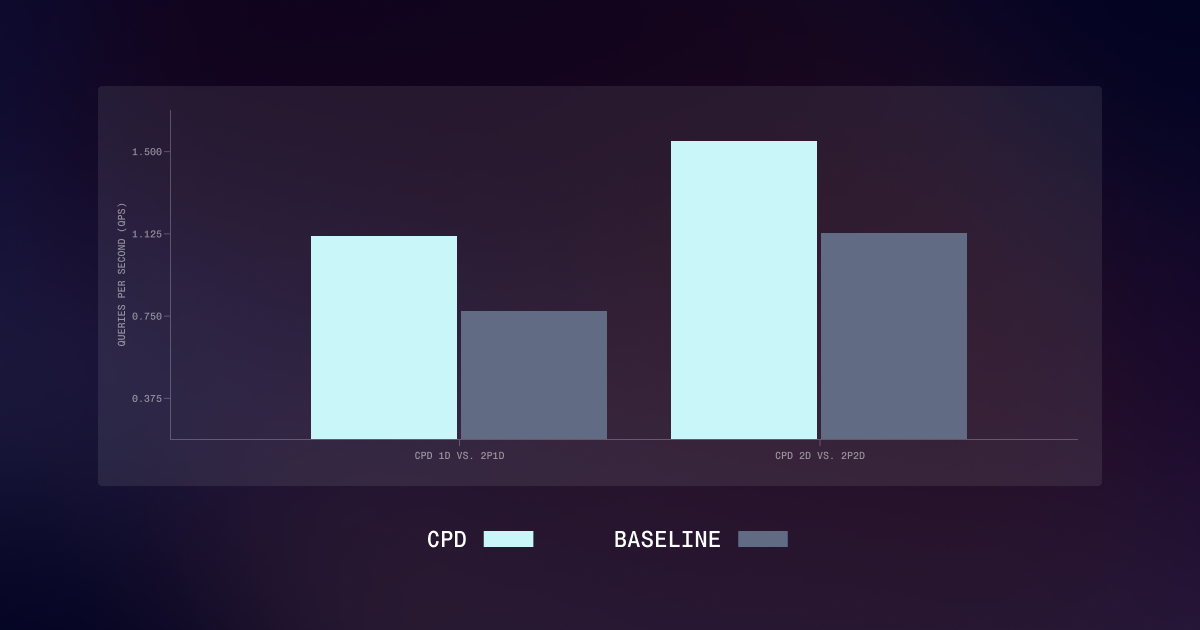
TL;DR: We turned on vLLM's prefix cache for our agent workloads at Nexus Labs and watched TTFT drop from 480ms to 110ms on one tenant and stay exactly the same on another. The split wasn't about traffic volume. It was about how each team templated their system prompts.
The setup
Our fine-tuning team serves 14 enterprise agents through a shared inference cluster. Four H100 nodes, vLLM 0.6.x, Qwen2.5-32B as the workhorse model. Traffic is bursty. One customer's nightly workflow can hit 8k requests in twenty minutes while another trickles through 30 calls an hour.
Before turning on prefix caching, average TTFT across the cluster sat at 410ms p50, 1.2s p95. Cost wasn't the urgent problem. Latency was, because agents loop. A 400ms TTFT on a 12-step plan turns into 4.8 seconds of dead time before the user sees anything.
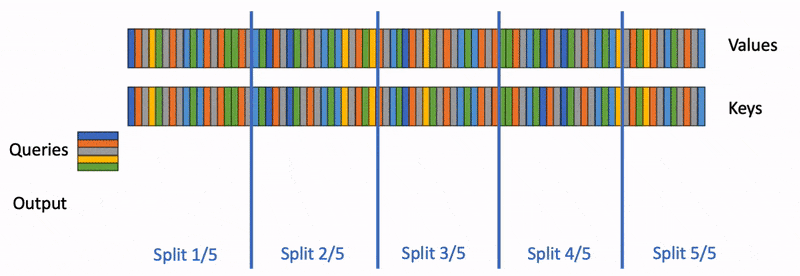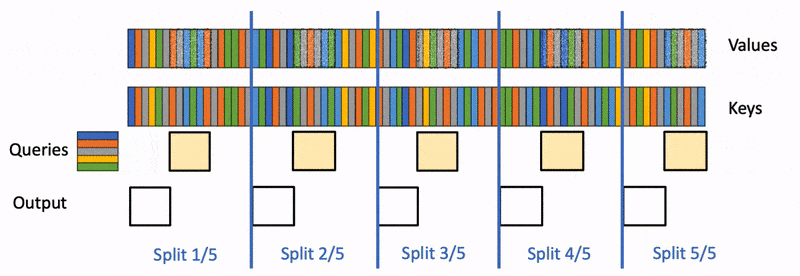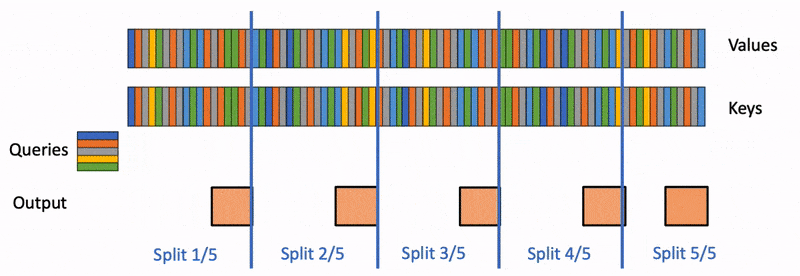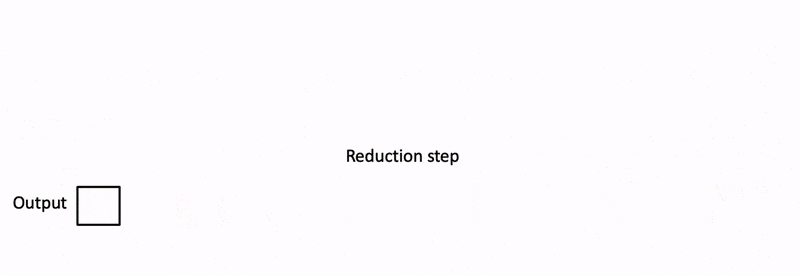
What the cache actually does