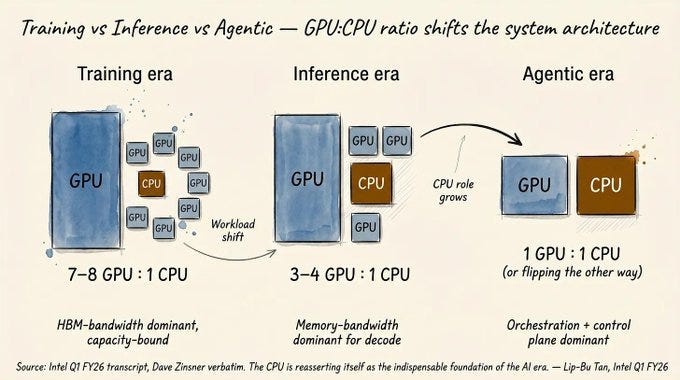
Training was a bounded investment event. Inference is an unbounded operational residency problem.
That distinction is the one most AI cost conversations refuse to make. The infrastructure budget conversation for AI has moved — not from "cheap" to "expensive," but from "event" to "permanent." Training had a finish line. Inference steady state does not. Every model you deploy occupies compute, serving infrastructure, and operational overhead continuously, for as long as the application runs. The cost clock never stops, and unlike traditional cloud workloads, there is no idle state that naturally reduces spend.
This matters architecturally because it changes what you are trying to govern. The optimization lever for a bounded workload is efficiency. The optimization lever for a permanently resident workload is authority — who decides what occupies infrastructure, on what terms, and with what accountability. Those are completely different governance problems.
The Inference Steady State Is Not a Phase — It's the New Baseline
Once a model is in production, it occupies infrastructure permanently. Endpoints stay warm because cold start latency violates SLOs. Concurrency headroom has to be reserved in advance. Routing layers, token caches, fallback models, and observability pipelines run continuously alongside the primary serving path.