Understand the problem
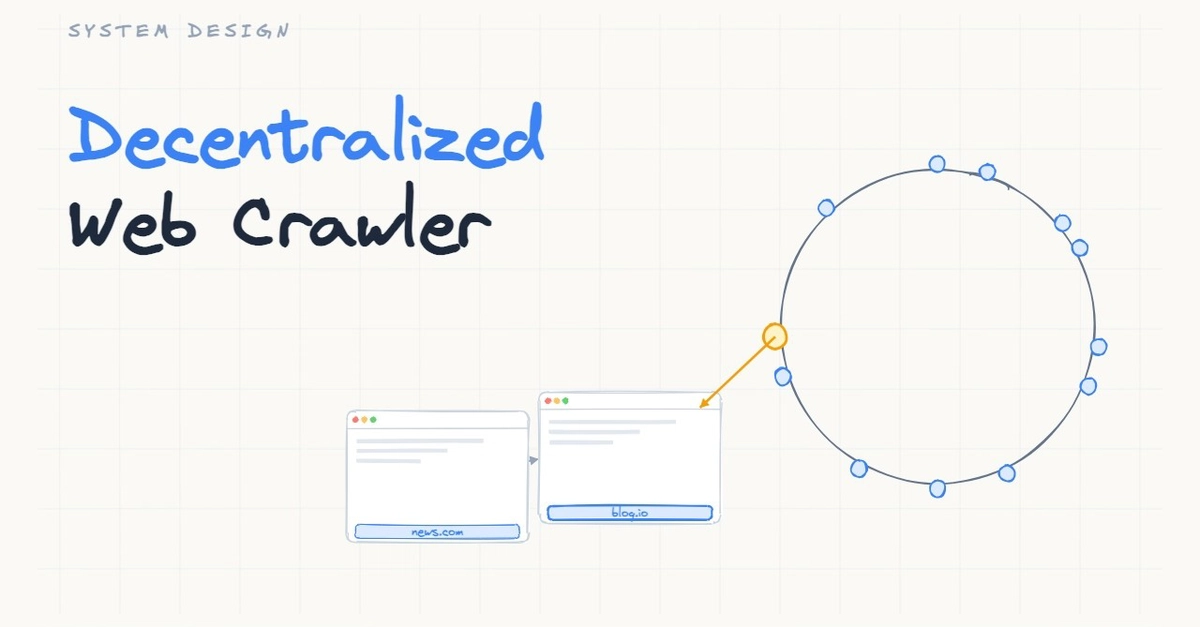
What we're building. A web crawler that runs across independent nodes with no central component. In a distributed crawler, many machines work together, but they still share infrastructure: a common URL queue, a common scheduler, a common database that tracks what has been crawled. In a decentralized crawler, none of that shared infrastructure exists. Each node runs independently, and the nodes have to agree on who crawls what without anyone coordinating them.
Functional requirements
Core:
Start from seed URLs and crawl reachable pages.





