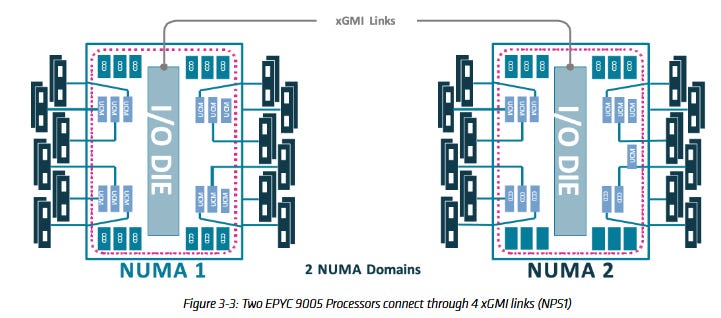
When most people think about running LLMs locally, they think about VRAM. But if you're running on a multi-socket server, there's a completely different bottleneck: NUMA memory topology. RAM Coffers is solving this.
The NUMA Problem
In a dual-socket or multi-socket server, each CPU has its own local memory bank. Accessing local RAM is fast. Accessing memory across the interconnect (Infinity Fabric on AMD, UPI on Intel) is 2-3x slower.
When an LLM inference engine doesn't know about NUMA topology, it can end up:
Allocating model weights on the wrong NUMA node