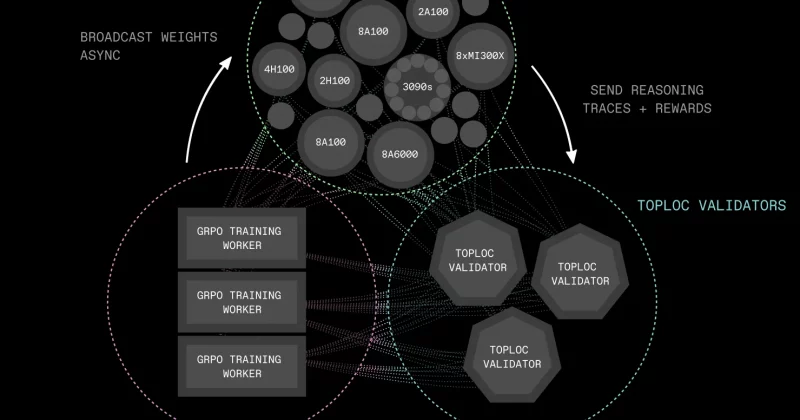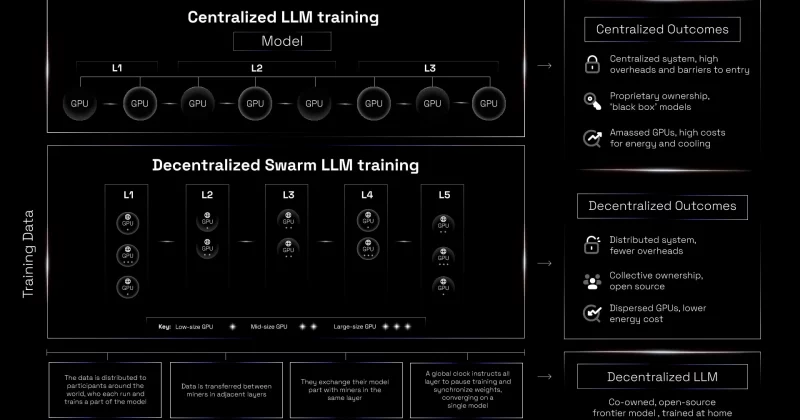
Training a large language model typically requires a warehouse full of GPUs, a seven-figure cloud computing bill, and the kind of organizational muscle only a handful of companies possess. Bittensor’s Subnet 9 is trying to flip that script with a new architecture called IOTA, short for Incentivised Orchestrated Training Architecture, which splits massive AI models across multiple machines so no single participant needs to hold the entire thing in memory.
From winner-takes-all to collective assembly line
Previous versions of SN9 operated on a competitive model. Miners essentially raced each other, and only top performers earned rewards. By August 2024, that setup had successfully pretrained large language models with up to 14 billion parameters.
But the winner-takes-all approach had a ceiling. It discouraged smaller contributors who couldn’t compete with well-resourced miners, and it created natural bottlenecks around what any individual machine could handle. IOTA, published on arXiv on July 16, 2025, rethinks the entire incentive structure.
Instead of isolated competitors, miners now function as nodes in a collaborative pipeline. The architecture integrates both pipeline parallelism and data parallelism, two techniques borrowed from how major AI labs already distribute training workloads internally. Rewards under IOTA are distributed proportionally among all pipeline miners based on their actual contribution, removing the primary disincentive for smaller GPU owners to participate.