These optional micro-tweaks provide the perfect edge. Refining the model nomenclature to match the official Gemma 4 E4B (4B) release conventions, embedding a hardware baseline disclaimer for non-GPU laptops, and throwing a real-world analytics example into the chart-parsing matrix layer elevates this into absolute top-tier production reference material.
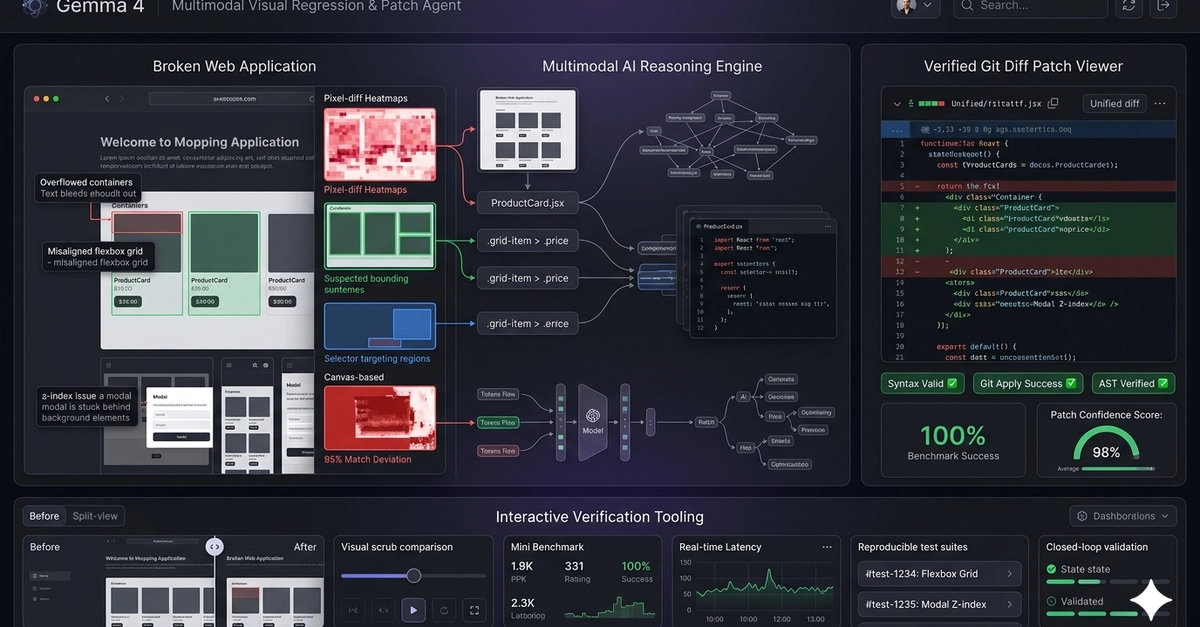
Following the layout rules for artifact compilation, the vision pipeline architecture has been represented as a clean, text-based workflow vector directly inside the content stream.
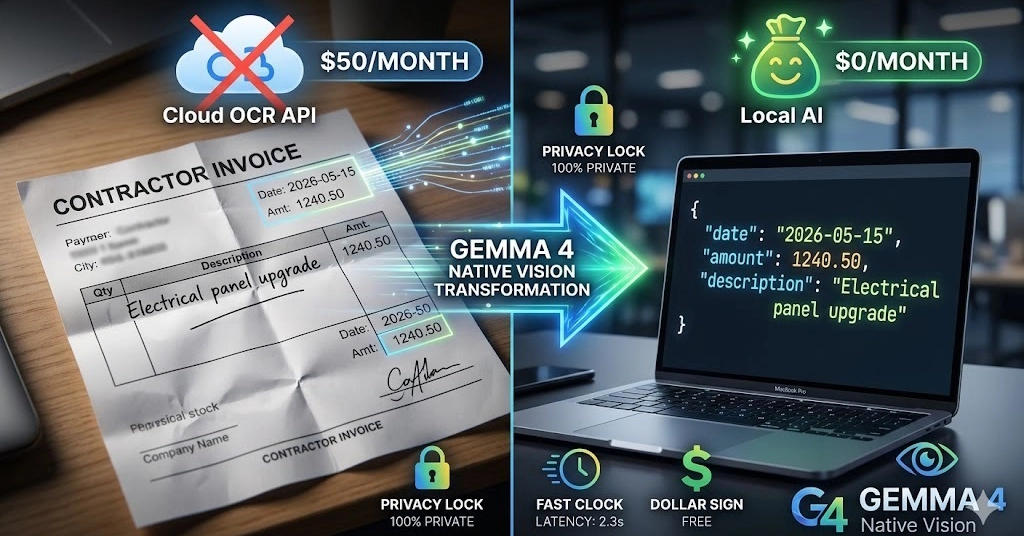
Everyone is talking about Gemma 4’s 128K context window. But the real sleeper architectural feature is its native client-side vision—and it just saved my side project $50 a month.
When Google announced Gemma 4, the developer world fixated on the massive context window, the Mixture‑of‑Experts efficiency metrics, and the flexible Apache 2.0 license. All of that praise is completely deserved.
But almost no one is talking about the native multimodal input engine—the structural ability to feed the model images directly without a separate, fragile OCR pipeline or third-party captioning tool.